A prelude to machine learning
What is machine learning?
The term machine learning gets a lot of airtime in the popular and trade press these days. As I started writing this article, I did a quick search for recent news headlines that contained this term. Here are the top three results with datelines within three days of the search:
The truth about hype usually tends to be quite prosaic and so it is in this case. Machine learning, as Professor Yaser Abu-Mostafa puts it, is simply about “learning from data.” And although the professor is referring to computers, this is so for humans too – we learn through patterns discerned from sensory data. As he states in the first few lines of his wonderful (but mathematically demanding!) book entitled, Learning From Data:
If you show a picture to a three-year-old and ask if there’s a tree in it, you will likely get a correct answer. If you ask a thirty year old what the definition of a tree is, you will likely get an inconclusive answer. We didn’t learn what a tree is by studying a [model] of what trees [are]. We learned by looking at trees. In other words, we learned from data.
In other words, the three year old forms a model of what constitutes a tree through a process of discerning a common pattern between all objects that grown-ups around her label “trees.” (the data). She can then “predict” that something is (or is not) a tree by applying this model to new instances presented to her.
This is exactly what happens in machine learning: the computer (or more correctly, the algorithm) builds a predictive model of a variable (like “treeness”) based on patterns it discerns in data. The model can then be applied to predict the value of the variable (e.g. is it a tree or not) in new instances.
With that said for an introduction, it is worth contrasting this machine-driven process of model building with the traditional approach of building mathematical models to predict phenomena as in, say, physics and engineering.
What are models good for?
Physicists and engineers model phenomena using physical laws and mathematics. The aim of such modelling is both to understand and predict natural phenomena. For example, a physical law such as Newton’s Law of Gravitation is itself a model – it helps us understand how gravity works and make predictions about (say) where Mars is going to be six months from now. Indeed, all theories and laws of physics are but models that have wide applicability.
(Aside: Models are typically expressed via differential equations. Most differential equations are hard to solve analytically (or exactly), so scientists use computers to solve them numerically. It is important to note that in this case computers are used as calculation tools, they play no role in model-building.)
As mentioned earlier, the role of models in the sciences is twofold – understanding and prediction. In contrast, in machine learning the focus is usually on prediction rather than understanding. The predictive successes of machine learning have led certain commentators to claim that scientific theory building is obsolete and science can advance by crunching data alone. Such claims are overblown, not to mention, hubristic, for although a data scientist may be able to predict with accuracy, he or she may not be able to tell you why a particular prediction is obtained. This lack of understanding can mislead and can even have harmful consequences, a point that’s worth unpacking in some detail…
Assumptions, assumptions
A model of a real world process or phenomenon is necessarily a simplification. This is essentially because it is impossible to isolate a process or phenomenon from the rest of the world. As a consequence it is impossible to know for certain that the model one has built has incorporated all the interactions that influence the process / phenomenon of interest. It is quite possible that potentially important variables have been overlooked.
The selection of variables that go into a model is based on assumptions. In the case of model building in physics, these assumptions are made upfront and are thus clear to anybody who takes the trouble to read the underlying theory. In machine learning, however, the assumptions are harder to see because they are implicit in the data and the algorithm. This can be a problem when data is biased or an algorithm opaque.
Problem of bias and opacity become more acute as datasets increase in size and algorithms become more complex, especially when applied to social issues that have serious human consequences. I won’t go into this here, but for examples the interested reader may want to have a look at Cathy O’Neil’s book, Weapons of Math Destruction, or my article on the dark side of data science.
As an aside, I should point out that although assumptions are usually obvious in traditional modelling, they are often overlooked out of sheer laziness or, more charitably, lack of awareness. This can have disastrous consequences. The global financial crisis of 2008 can – to some extent – be blamed on the failure of trading professionals to understand assumptions behind the model that was used to calculate the value of collateralised debt obligations.
It all starts with a straight line….
Now that we’ve taken a tour of some of the key differences between model building in the old and new worlds, we are all set to start talking about machine learning proper.
I should begin by admitting that I overstated the point about opacity: there are some machine learning algorithms that are transparent as can possibly be. Indeed, chances are you know the algorithm I’m going to discuss next, either from an introductory statistics course in university or from plotting relationships between two variables in your favourite spreadsheet. Yea, you may have guessed that I’m referring to linear regression.
In its simplest avatar, linear regression attempts to fit a straight line to a set of data points in two dimensions. The two dimensions correspond to a dependent variable (traditionally denoted by 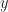


Figure 1: Linear Regression
Figure 1 also serves to illustrate that linear models are going to be inappropriate in most real world situations (the straight line does not fit the data well). But it is not so hard to devise methods to fit more complicated functions.
The important point here is that since machine learning is about finding functions that accurately predict dependent variables for as yet unknown values of the independent variables, most algorithms make explicit or implicit choices about the form of these functions.
Complexity versus simplicity
At first sight it seems a no-brainer that complicated functions will work better than simple ones. After all, if we choose a nonlinear function with lots of parameters, we should be able to fit a complex data set better than a linear function can (See Figure 2 – the complicated function fits the datapoints better than the straight line). But there’s catch: although the ability to fit a dataset increases with the flexibility of the fitting function, increasing complexity beyond a point will invariably reduce predictive power. Put another way, a complex enough function may fit the known data points perfectly but, as a consequence, will inevitably perform poorly on unknown data. This is an important point so let’s look at it in greater detail.

Figure 2: Simple and complex fitting function (courtesy: Wikimedia)
Recall that the aim of machine learning is to predict values of the dependent variable for as yet unknown values of the independent variable(s). Given a finite (and usually, very limited) dataset, how do we build a model that we can have some confidence in? The usual strategy is to partition the dataset into two subsets, one containing 60 to 80% of the data (called the training set) and the other containing the remainder (called the test set). The model is then built – i.e. an appropriate function fitted – using the training data and verified against the test data. The verification process consists of comparing the predicted values of the dependent variable with the known values for the test set.
Now, it should be intuitively clear that the more complicated the function, the better it will fit the training data.
Question: Why?
Answer: Because complicated functions have more free parameters – for example, linear functions of a single (dependent) variable have two parameters (slope and intercept), quadratics have three, cubics four and so on. The mathematician, John von Neumann is believed to have said, “With four parameters I can fit an elephant, and with five I can make him wiggle his trunk.” See this post for a nice demonstration of the literal truth of his words.
Put another way, complex functions are wrigglier than simple ones, and – by suitable adjustment of parameters – their “wriggliness” can be adjusted to fit the training data better than functions that are less wriggly. Figure 2 illustrates this point well.
This may sound like you can have your cake and eat it too: choose a complicated enough function and you can fit both the training and test data well. Not so! Keep in mind that the resulting model (fitted function) is built using the training set alone, so a good fit to the test data is not guaranteed. In fact, it is intuitively clear that a function that fits the training data perfectly (as in Figure 2) is likely to do a terrible job on the test data.
Question: Why?
Answer: Remember, as far as the model is concerned, the test data is unknown. Hence, the greater the wriggliness in the trained model, the less likely it is to fit the test data well. Remember, once the model is fitted to the training data, you have no freedom to tweak parameters any further.
This tension between simplicity and complexity of models is one of the key principles of machine learning and is called the bias-variance tradeoff. Bias here refers to lack of flexibility and variance, the reducible error. In general simpler functions have greater bias and lower variance and complex functions, the opposite. Much of the subtlety of machine learning lies in developing an understanding of how to arrive at the right level of complexity for the problem at hand – that is, how to tweak parameters so that the resulting function fits the training data just well enough so as to generalise well to unknown data.
Note: those who are curious to learn more about the bias-variance tradeoff may want to have a look at this piece. For details on how to achieve an optimal tradeoff, search for articles on regularization in machine learning.
Unlocking unstructured data
The discussion thus far has focused primarily on quantitative or enumerable data (numbers and categories) that’s stored in a structured format – i.e. as columns and rows in a spreadsheet or database table). This is fine as it goes, but the fact is that much of the data in organisations is unstructured, the most common examples being text documents and audio-visual media. This data is virtually impossible to analyse computationally using relational database technologies (such as SQL) that are commonly used by organisations.
The situation has changed dramatically in the last decade or so. Text analysis techniques that once required expensive software and high-end computers have now been implemented in open source languages such as Python and R, and can be run on personal computers. For problems that require computing power and memory beyond that, cloud technologies make it possible to do so cheaply. In my opinion, the ability to analyse textual data is the most important advance in data technologies in the last decade or so. It unlocks a world of possibilities for the curious data analyst. Just think, all those comment fields in your survey data can now be analysed in a way that was never possible in the relational world!
There is a general impression that text analysis is hard. Although some of the advanced techniques can take a little time to wrap one’s head around, the basics are simple enough. Yea, I really mean that – for proof, check out my tutorial on the topic.
Wrapping up
I could go on for a while. Indeed, I was planning to delve into a few algorithms of increasing complexity (from regression to trees and forests to neural nets) and then close with a brief peek at some of the more recent headline-grabbing developments like deep learning. However, I realised that such an exploration would be too long and (perhaps more importantly) defeat the main intent of this piece which is to give starting students an idea of what machine learning is about, and how it differs from preexisting techniques of data analysis. I hope I have succeeded, at least partially, in achieving that aim.
For those who are interested in learning more about machine learning algorithms, I can suggest having a look at my “Gentle Introduction to Data Science using R” series of articles. Start with the one on text analysis (link in last line of previous section) and then move on to clustering, topic modelling, naive Bayes, decision trees, random forests and support vector machines. I’m slowly adding to the list as I find the time, so please do check back again from time to time.
Note: This post is written as an introduction to the Data, Algorithms and Meaning subject that is part of the core curriculum of the Master of Data Science and Innovation program at UTS. I’m co-teaching the subject in Autumn 2018 with Alex Scriven and Rory Angus.



Thank you for nice introduction
LikeLike
Limbu
March 3, 2017 at 1:51 am
A very good intro.
“Just think, all those comment fields in your survey data can now be analysed in a way that was never possible in the relational world!”
I have to nitpick here – the “relational world” reference is ambiguous. You can talk about the limits of traditional relational DBMSs in terms of processing power and suitability for the job, and you’d be correct, but there’s nothing inherently in the relational model which prevents you from making a logical model of natural language text.
I strongly recommend reading Fabian Pascal on these topics. He often comes across quite abrasive but he is a must read before one makes any assertions about the relational model (e.g. the principle of physical independence).
LikeLiked by 1 person
Andrew G
March 7, 2017 at 9:18 am
Hi Andrew,
Many thanks for reading and taking the time to comment. I agree, my comments were about relational database products available in the market rather than the relational model per se. I read some of Fabian Pascal’s work a long time (10 years?) ago. Must go back to it when I find the time.
That said, logical models may not be very useful for extracting information from text, primarily because of the multitude of ways in which a single idea can be expressed. The recent successes of word embedding techniques suggest that statistical approaches might be more promising (this article by Peter Norvig, which compares both approaches, is relevant here). I reckon the best results would likely come from some kind of merging of both approaches …and that’s a story yet to unfold.
Thanks again!
Regards,
Kailash.
LikeLike
K
March 9, 2017 at 10:04 pm
Thanks for a great post here K!
LikeLiked by 1 person
Dan Herr
March 25, 2017 at 9:01 am
Thanks for the feedback Dan, much appreciated!
LikeLike
K
March 25, 2017 at 12:05 pm
[…] overfitting by using less complicated functions (and if that means nothing to you, check out my prelude to machine learning). One way to do this is toss out less important variables, after checking that they aren’t […]
LikeLike
A gentle introduction to logistic regression and lasso regularisation using R | Eight to Late
July 11, 2017 at 10:00 pm
[…] an aside, note that much of what goes under the banner of machine learning and AI can be also classed as first order […]
LikeLike
Learning, evolution and the future of work | Eight to Late
July 5, 2018 at 6:06 pm