Archive for February 2016
A gentle introduction to decision trees using R
Introduction
Most techniques of predictive analytics have their origins in probability or statistical theory (see my post on Naïve Bayes, for example). In this post I’ll look at one that has more a commonplace origin: the way in which humans make decisions. When making decisions, we typically identify the options available and then evaluate them based on criteria that are important to us. The intuitive appeal of such a procedure is in no small measure due to the fact that it can be easily explained through a visual. Consider the following graphic, for example:

Figure 1: Example of a simple decision tree (Courtesy: Duncan Hull)
(Original image: https://www.flickr.com/photos/dullhunk/7214525854, Credit: Duncan Hull)
The tree structure depicted here provides a neat, easy-to-follow description of the issue under consideration and its resolution. The decision procedure is based on asking a series of questions, each of which serve to further reduce the domain of possibilities. The predictive technique I discuss in this post,classification and regression trees (CART), works in much the same fashion. It was invented by Leo Breiman and his colleagues in the 1970s.
In what follows, I will use the open source software, R. If you are new to R, you may want to follow this link for more on the basics of setting up and installing it. Note that the R implementation of the CART algorithm is called RPART (Recursive Partitioning And Regression Trees). This is essentially because Breiman and Co. trademarked the term CART. As some others have pointed out, it is somewhat ironical that the algorithm is now commonly referred to as RPART rather than by the term coined by its inventors.
A bit about the algorithm
The rpart algorithm works by splitting the dataset recursively, which means that the subsets that arise from a split are further split until a predetermined termination criterion is reached. At each step, the split is made based on the independent variable that results in the largest possible reduction in heterogeneity of the dependent (predicted) variable.
Splitting rules can be constructed in many different ways, all of which are based on the notion of impurity- a measure of the degree of heterogeneity of the leaf nodes. Put another way, a leaf node that contains a single class is homogeneous and has impurity=0. There are three popular impurity quantification methods: Entropy (aka information gain), Gini Index and Classification Error. Check out this article for a simple explanation of the three methods.
The rpart algorithm offers the entropy and Gini index methods as choices. There is a fair amount of fact and opinion on the Web about which method is better. Here are some of the better articles I’ve come across:
https://www.garysieling.com/blog/sklearn-gini-vs-entropy-criteria
http://www.salford-systems.com/resources/whitepapers/114-do-splitting-rules-really-matter
The answer as to which method is the best is: it depends. Given this, it may be prudent to try out a couple of methods and pick the one that works best for your problem.
Regardless of the method chosen, the splitting rules partition the decision space (a fancy word for the entire dataset) into rectangular regions each of which correspond to a split. Consider the following simple example with two predictors x1 and x2. The first split is at x1=1 (which splits the decision space into two regions x11), the second at x2=2, which splits the (x1>1) region into 2 sub-regions, and finally x1=1.5 which splits the (x1>1,x2>2) sub-region further.

Figure 2: Example of partitioning
It is important to note that the algorithm works by making the best possible choice at each particular stage, without any consideration of whether those choices remain optimal in future stages. That is, the algorithm makes a locally optimal decision at each stage. It is thus quite possible that such a choice at one stage turns out to be sub-optimal in the overall scheme of things. In other words, the algorithm does not find a globally optimal tree.
Another important point relates to well-known bias-variance tradeoff in machine learning, which in simple terms is a tradeoff between the degree to which a model fits the training data and its predictive accuracy. This refers to the general rule that beyond a point, it is counterproductive to improve the fit of a model to the training data as this increases the likelihood of overfitting. It is easy to see that deep trees are more likely to overfit the data than shallow ones. One obvious way to control such overfitting is to construct shallower trees by stopping the algorithm at an appropriate point based on whether a split significantly improves the fit. Another is to grow a tree unrestricted and then prune it back using an appropriate criterion. The rpart algorithm takes the latter approach.
Here is how it works in brief:
Essentially one minimises the cost, 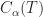



First, we note that when 

An implication of their tendency to overfit data is that decision trees tend to be sensitive to relatively minor changes in the training datasets. Indeed, small differences can lead to radically different looking trees. Pruning addresses this to an extent, but does not resolve it completely. A better resolution is offered by the so-called ensemble methods that average over many differently constructed trees. I’ll discuss one such method at length in a future post.
Finally, I should also mention that decision trees can be used for both classification and regression problems (i.e. those in which the predicted variable is discrete and continuous respectively). I’ll demonstrate both types of problems in the next two sections.
Classification trees using rpart
To demonstrate classification trees, we’ll use the Ionosphere dataset available in the mlbench package in R. I have chosen this dataset because it nicely illustrates the points I wish to make in this post. In general, you will almost always find that algorithms that work fine on classroom datasets do not work so well in the real world…but of course, you know that already!
We begin by setting the working directory, loading the required packages (rpart and mlbench) and then loading the Ionosphere dataset.
Next we separate the data into training and test sets. We’ll use the former to build the model and the latter to test it. To do this, I use a simple scheme wherein I randomly select 80% of the data for the training set and assign the remainder to the test data set. This is easily done in a single R statement that invokes the uniform distribution (runif) and the vectorised function, ifelse. Before invoking runif, I set a seed integer to my favourite integer in order to ensure reproducibility of results.
In the above, I have also removed the training flag from the training and test datasets.
Next we invoke rpart. I strongly recommend you take some time to go through the documentation and understand the parameters and their defaults values. Note that we need to remove the predicted variable from the dataset before passing the latter on to the algorithm, which is why we need to find the column index of the predicted variable (first line below). Also note that we set the method parameter to “class“, which simply tells the algorithm that the predicted variable is discrete. Finally, rpart uses Gini rule for splitting by default, and we’ll stick with this option.
The resulting plot is shown in Figure 3 below. It is quite self-explanatory so I won’t dwell on it here.

Figure 3: A classification tree for Ionosphere dataset
Next we see how good the model is by seeing how it fares against the test data.
| pred true | bad | good |
| bad | 17 | 2 |
| good | 9 | 43 |
Note that we need to verify the above results by doing multiple runs, each using different training and test sets. I will do this later, after discussing pruning.
Next, we prune the tree using the cost complexity criterion. Basically, the intent is to see if a shallower subtree can give us comparable results. If so, we’d be better of choosing the shallower tree because it reduces the likelihood of overfitting.
As described earlier, we choose the appropriate pruning parameter (aka cost-complexity parameter)
| CP | nsplit | rel error | xerror | xstd | |
| 1 | 0.57 | 0 | 1.00 | 1.00 | 0.080178 |
| 2 | 0.20 | 1 | 0.43 | 0.46 | 0.062002 |
| 3 | 0.02 | 2 | 0.23 | 0.26 | 0.048565 |
| 4 | 0.01 | 4 | 0.19 | 0.35 |
It is clear from the above, that the lowest cross-validation error (xerror in the table) occurs for 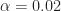
Next, we prune the tree based on this value of CP:
Note that rpart will use a default CP value of 0.01 if you don’t specify one in prune.
The pruned tree is shown in Figure 4 below.

Figure 4: A pruned classification tree for Ionosphere dataset
Let’s see how this tree stacks up against the fully grown one shown in Fig 3.
This seems like an improvement over the unpruned tree, but one swallow does not a summer make. We need to check that this holds up for different training and test sets. This is easily done by creating multiple random partitions of the dataset and checking the efficacy of pruning for each. To do this efficiently, I’ll create a function that takes the training fraction, number of runs (partitions) and the name of the dataset as inputs and outputs the proportion of correct predictions for each run. It also optionally prunes the tree. Here’s the code:
Note that in the above, I have set the default value of the prune_tree to FALSE, so the function will execute the first branch of the if statement unless the default is overridden.
OK, so let’s do 50 runs with and without pruning, and check the mean and variance of the results for both sets of runs.
So we see that there is an improvement of about 3% with pruning. Also, if you were to plot the trees as we did earlier, you would see that this improvement is achieved with shallower trees. Again, I point out that this is not always the case. In fact, it often happens that pruning results in worse predictions, albeit with better reliability – a classic illustration of the bias-variance tradeoff.
Regression trees using rpart
In the previous section we saw how one can build decision trees for situations in which the predicted variable is discrete. Let’s now look at the case in which the predicted variable is continuous. We’ll use the Boston Housing dataset from the mlbench package. Much of the discussion of the earlier section applies here, so I’ll just display the code, explaining only the differences.
Next we invoke rpart, noting that the predicted variable is medv (median value of owner-occupied homes in $1000 units) and that we need to set the method parameter to “anova“. The latter tells rpart that the predicted variable is continuous (i.e that this is a regression problem).
The plot of the tree is shown in Figure 5 below.

Figure 5: A regression tree for Boston Housing dataset
Next, we need to see how good the predictions are. Since the dependent variable is continuous, we cannot compare the predictions directly against the test set. Instead, we calculate the root mean square (RMS) error. To do this, we request rpart to output the predictions as a vector – one prediction per record in the test dataset. The RMS error can then easily be calculated by comparing this vector with the medv column in the test dataset.
Here is the relevant code:
Again, we need to do multiple runs to check on the reliability of the predictions. However, you already know how to do that so I will leave it to you.
Moving on, we prune the tree using the cost complexity criterion as before. The code is exactly the same as in the classification problem.
The tree is unchanged so I won’t show it here. This means, as far as the cost complexity pruning is concerned, the optimal subtree is the same as the original tree. To confirm this, we’d need to do multiple runs as before – something that I’ve already left as as an exercise for you :). Basically, you’ll need to write a function analogous to the one above, that computes the root mean square error instead of the proportion of correct predictions.
Wrapping up
This brings us to the end of my introduction to classification and regression trees using R. Unlike some articles on the topic I have attempted to describe each of the steps in detail and provide at least some kind of a rationale for them. I hope you’ve found the description and code snippets useful.
I’ll end by reiterating a couple points I made early in this piece. The nice thing about decision trees is that they are easy to explain to the users of our predictions. This is primarily because they reflect the way we think about how decisions are made in real life – via a set of binary choices based on appropriate criteria. That said, in many practical situations decision trees turn out to be unstable: small changes in the dataset can lead to wildly different trees. It turns out that this limitation can be addressed by building a variety of trees using different starting points and then averaging over them. This is the domain of the so-called random forest algorithm.We’ll make the journey from decision trees to random forests in a future post.
Postscript, 20th September 2016: I finally got around to finishing my article on random forests.


