A gentle introduction to random forests using R
Introduction
In a previous post, I described how decision tree algorithms work and demonstrated their use via the rpart library in R. Decision trees work by splitting a dataset recursively. That is, subsets arising from a split are further split until a predetermined termination criterion is reached. At each step, a split is made based on the independent variable that results in the largest possible reduction in heterogeneity of the dependent variable.
(Note: readers unfamiliar with decision trees may want to read that post before proceeding)
The main drawback of decision trees is that they are prone to overfitting. The reason for this is that trees, if grown deep, are able to fit all kinds of variations in the data, including noise. Although it is possible to address this partially by pruning, the result often remains less than satisfactory. This is because the algorithm makes a locally optimal choice at each split without any regard to whether the choice made is the best one overall. A poor split made in the initial stages can thus doom the model, a problem that cannot be fixed by post-hoc pruning.
In this post I describe random forests, a tree-based algorithm that addresses the above shortcoming of decision trees. I’ll first describe the intuition behind the algorithm via an analogy and then do a demo using the R randomForest library.
Motivating random forests
One of the reasons for the popularity of decision trees is that they reflect the way humans make decisions: by weighing up options at each stage and choosing the best one available. The analogy is particularly useful because it also suggests how decision trees can be improved.
One of the lifelines in the game show, Who Wants to be A Millionaire, is “Ask The Audience” wherein a contestant can ask the audience to vote on the answer to a question. The rationale here is that the majority response from a large number of independent decision makers is more likely to yield a correct answer than one from a randomly chosen person. There are two factors at play here:
- People have different experiences and will therefore draw upon different “data” to answer the question.
- People have different knowledge bases and preferences and will therefore draw upon different “variables” to make their choices at each stage in their decision process.
Taking a cue from the above, it seems reasonable to build many decision trees using:
- Different sets of training data.
- Randomly selected subsets of variables at each split of every decision tree.
Predictions can then made by taking the majority vote over all trees (for classification problems) or averaging results over all trees (for regression problems). This is essentially how the random forest algorithm works.
The net effect of the two strategies is to reduce overfitting by a) averaging over trees created from different samples of the dataset and b) decreasing the likelihood of a small set of strong predictors dominating the splits. The price paid is reduced interpretability as well as increased computational complexity. But then, there is no such thing as a free lunch.
The mechanics of the algorithm
Although we will not delve into the mathematical details of the algorithm, it is important to understand how two points made above are implemented in the algorithm.
Bootstrap aggregating… and a (rather cool) error estimate
A key feature of the algorithm is the use of multiple datasets for training individual decision trees. This is done via a neat statistical trick called bootstrap aggregating (also called bagging).
Here’s how bagging works:
Assume you have a dataset of size N. From this you create a sample (i.e. a subset) of size n (n less than or equal to N) by choosing n data points randomly with replacement. “Randomly” means every point in the dataset is equally likely to be chosen and “with replacement” means that a specific data point can appear more than once in the subset. Do this M times to create M equally-sized samples of size n each. It can be shown that this procedure, which statisticians call bootstrapping, is legit when samples are created from large datasets – that is, when N is large.
Because a bagged sample is created by selection with replacement, there will generally be some points that are not selected. In fact, it can be shown that, on the average, each sample will use about two-thirds of the available data points. This gives us a clever way to estimate the error as part of the process of model building.
Here’s how:
For every data point, obtain predictions for trees in which the point was out of bag. From the result mentioned above, this will yield approximately M/3 predictions per data point (because a third of the data points are out of bag). Take the majority vote of these M/3 predictions as the predicted value for the data point. One can do this for the entire dataset. From these out of bag predictions for the whole dataset, we can estimate the overall error by computing a classification error (Count of correct predictions divided by N) for classification problems or the root mean squared error for regression problems. This means there is no need to have a separate test data set, which is kind of cool. However, if you have enough data, it is worth holding out some data for use as an independent test set. This is what we’ll do in the demo later.
Using subsets of predictor variables
Although bagging reduces overfitting somewhat, it does not address the issue completely. The reason is that in most datasets a small number of predictors tend to dominate the others. These predictors tend to be selected in early splits and thus influence the shapes and sizes of a significant fraction of trees in the forest. That is, strong predictors enhance correlations between trees which tends to come in the way of variance reduction.
A simple way to get around this problem is to use a random subset of variables at each split. This avoids over-representation of dominant variables and thus creates a more diverse forest. This is precisely what the random forest algorithm does.
Random forests in R
In what follows, I use the famous Glass dataset from the mlbench library. The dataset has 214 data points of six types of glass with varying metal oxide content and refractive indexes. I’ll first build a decision tree model based on the data using the rpart library (recursive partitioning) that I covered in an earlier article and then use then show how one can build a random forest model using the randomForest library. The rationale behind this is to compare the two models – single decision tree vs random forest. In the interests of space, I won’t explain details of the rpart here as I’ve covered it at length in the previous article. However, for completeness, I’ll list the demo code for it before getting into random forests.
Decision trees using rpart
Here’s the code listing for building a decision tree using rpart on the Glass dataset (please see my previous article for a full explanation of each step). Note that I have not used pruning as there is little benefit to be gained from it (Exercise for the reader: try this for yourself!).
Now, we know that decision tree algorithms tend to display high variance so the hit rate from any one tree is likely to be misleading. To address this we’ll generate a bunch of trees using different training sets (via random sampling) and calculate an average hit rate and spread (or standard deviation).
The decision tree algorithm gets it right about 69% of the time with a variation of about 5%. The variation isn’t too bad here, but the accuracy has hardly improved at all (Exercise for the reader: why?). Let’s see if we can do better using random forests.
Random forests
As discussed earlier, a random forest algorithm works by averaging over multiple trees using bootstrapped samples. Also, it reduces the correlation between trees by splitting on a random subset of predictors at each node in tree construction. The key parameters for randomForest algorithm are the number of trees (ntree) and the number of variables to be considered for splitting (mtry). The algorithm sets a default of 500 for ntree and sets mtry to the square root of the the number of predictors for classification problems or one-third the total number of predictors for regression. These defaults can be overridden by explicitly providing values for these variables.
The preliminary stuff – the creation of training and test datasets etc. – is much the same as for decision trees but I’ll list the code for completeness.
randomForest(formula = Type ~ ., data = trainGlass, importance = TRUE, xtest = testGlass[, -typeColNum], ntree = 1001)
| 1 | 2 | 3 | 5 | 6 | 7 | class.error | |
| 1 | 40 | 7 | 2 | 0 | 0 | 0 | 0.1836735 |
| 2 | 8 | 49 | 1 | 2 | 2 | 1 | 0.2222222 |
| 3 | 6 | 3 | 6 | 0 | 0 | 0 | 0.6000000 |
| 5 | 0 | 1 | 0 | 11 | 0 | 1 | 0.1538462 |
| 6 | 1 | 2 | 0 | 1 | 6 | 0 | 0.5000000 |
| 7 | 1 | 2 | 0 | 1 | 0 | 21 | 0.1600000 |
The first thing to note is the out of bag error estimate is ~ 24%. Equivalently the hit rate is 76%, which is better than the 69% for decision trees. Secondly, you’ll note that the algorithm does a terrible job identifying type 3 and 6 glasses correctly. This could possibly be improved by a technique called boosting, which works by iteratively improving poor predictions made in earlier stages. I plan to look at boosting in a future post, but if you’re curious, check out the gbm package in R.
Finally, for completeness, let’s see how the test set does:
| 1 | 2 | 3 | 5 | 6 | 7 | |
| 1 | 19 | 2 | 0 | 0 | 0 | 0 |
| 2 | 1 | 9 | 1 | 0 | 0 | 0 |
| 3 | 1 | 1 | 1 | 0 | 0 | 0 |
| 5 | 0 | 1 | 0 | 0 | 0 | 0 |
| 6 | 0 | 0 | 0 | 0 | 3 | 0 |
| 7 | 0 | 0 | 0 | 0 | 0 | 4 |
The test accuracy is better than the out of bag accuracy and there are some differences in the class errors as well. However, overall the two compare quite well and are significantly better than the results of the decision tree algorithm.
Variable importance
Random forest algorithms also give measures of variable importance. Computation of these is enabled by setting importance, a boolean parameter, to TRUE. The algorithm computes two measures of variable importance: mean decrease in Gini and mean decrease in accuracy. Brief explanations of these follow.
Mean decrease in Gini
When determining splits in individual trees, the algorithm looks for the largest class (in terms of population) and attempts to isolate it first. If this is not possible, it tries to do the best it can, always focusing on isolating the largest remaining class in every split.This is called the Gini splitting rule (see this article for a good explanation of the rule).
The “goodness of split” is measured by the Gini Impurity, 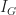

where 

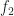
Mean decrease in accuracy
The mean decrease in accuracy is calculated using the out of bag data points for each tree. The procedure goes as follows: when a particular tree is grown, the out of bag points are passed down the tree and the prediction accuracy (based on all out of bag points) recorded . The predictors are then randomly permuted and the out of bag prediction accuracy recalculated. The decrease in accuracy for a given predictor is the difference between the accuracy of the original (unpermuted) tree and the those obtained from the permuted trees in which the predictor was excluded. As in the previous case, the decrease in accuracy for each predictor can be computed and tracked as the algorithm progresses. These can then be averaged by predictor to yield a mean decrease in accuracy.
Variable importance plot
From the above, it would seem that the mean decrease in accuracy is a more global measure as it uses fully constructed trees in contrast to the Gini measure which is based on individual splits. In practice, however, there could be other reasons for choosing one over the other…but that is neither here nor there, if you set importance to TRUE, you’ll get both. The numerical measures of importance are returned in the randomForest object (Glass.rf in our case), but I won’t list them here. Instead, I’ll just print out the variable importance plots for the two measures as these give a good visual overview of the relative importance of variables. The code is a simple one-liner:
The plot is shown in Figure 1 below.

Figure 1: Variable importance plots
In this case the two measures are pretty consistent so it doesn’t really matter which one you choose.
Wrapping up
Random forests are an example of a general class of techniques called ensemble methods. These techniques are based on the principle that averaging over a large number of not-so-good models yields a more reliable prediction than a single model. This is true only if models in the group are independent of each other, which is precisely what bootstrap aggregation and predictor subsetting are intended to achieve.
Although considerably more complex than decision trees, the logic behind random forests is not hard to understand. Indeed, the intuitiveness of the algorithm together with its ease of use and accuracy have made it very popular in the machine learning community.



[…] Postscript, 20th September 2016: I finally got around to finishing my article on random forests. […]
LikeLike
A gentle introduction to decision trees using R | Eight to Late
September 20, 2016 at 9:56 pm
[…] A gentle introduction to random forests using R […]
LikeLike
daily 09/20/2016 | Cshonea's Blog
September 21, 2016 at 6:36 am
I’d just like to thank you for your article.
I finished up a bootcamp in R recently, and there we had a very brief introduction to decision trees and random forests (enough to know that they exist, can solve classification / regression problems, and that they are interesting)
You’re walk through here is damn near perfect. A slight improvement would be to explain the following…
1) heterogeneity (purity vs impurity)
2) termination criterion
3) Independent Variable, Dependent Variable, Predictors, Predicted, Classes, Features
The problem with the first two terms is just that they are scary. I’m not saying don’t use them, but I think it would be helpful to include a quick definition:
heterogeneity – diversity
termination criterion – criteria that depends on the *purity* of the data (impurity of course discussed in your excellent link!)
For (3) I’m just pointing out all the ways people talk about what are essentially *columns* in your data. Independent and dependent variables are fine (gets the point across, even if it’s not strictly true). My personal favorite is assumed predictors and predicted variables as it gets to the heart of what we are doing. No matter your preference, I just think a quick line or two equivocating any of the terms the reader is likely to have heard in the wild with the terms that you are using will help a lot of folks out.
Thank you for this excellent article!
LikeLiked by 2 people
Peter Bartlett
December 30, 2016 at 6:37 am
Hi Peter,
Thanks so much for your valuable feedback, it’s hugely appreciated!. Your points are taken and will be acted on (as soon as I get a chance.). Wishing you the very best for 2017.
Regards,
Kailash,
LikeLike
K
December 30, 2016 at 10:08 am
[…] separable. To check performance by class, one can create a confusion matrix as described in my post on random forests. I’ll leave this as an exercise for you. Another point is that we have used a […]
LikeLike
A gentle introduction to support vector machines using R | Eight to Late
February 7, 2017 at 8:27 pm
[…] of previous section) and then move on to clustering, topic modelling, naive Bayes, decision trees, random forests and support vector machines. I’m slowly adding to the list as I find the time, so please do check […]
LikeLike
A prelude to machine learning | Eight to Late
February 23, 2017 at 3:13 pm
You’re posts are really excellent. Intuition heavy but not totally absent minded of the underlying mathematics. Clear and concise with conceptual examples and data based ones including the code. As a grad student I regularly consult your blog for topics I run into and need to get the intuition for before tackling a paper. Thanks!
LikeLiked by 1 person
alex
February 2, 2018 at 10:51 pm