Archive for the ‘Text Mining’ Category
A gentle introduction to topic modeling using R
Introduction
The standard way to search for documents on the internet is via keywords or keyphrases. This is pretty much what Google and other search engines do routinely…and they do it well. However, as useful as this is, it has its limitations. Consider, for example, a situation in which you are confronted with a large collection of documents but have no idea what they are about. One of the first things you might want to do is to classify these documents into topics or themes. Among other things this would help you figure out if there’s anything interest while also directing you to the relevant subset(s) of the corpus. For small collections, one could do this by simply going through each document but this is clearly infeasible for corpuses containing thousands of documents.
Topic modeling – the theme of this post – deals with the problem of automatically classifying sets of documents into themes
The article is organised as follows: I first provide some background on topic modelling. The algorithm that I use, Latent Dirichlet Allocation (LDA), involves some pretty heavy maths which I’ll avoid altogether. However, I will provide an intuitive explanation of how LDA works before moving on to a practical example which uses the topicmodels library in R. As in my previous articles in this series (see this post and this one), I will discuss the steps in detail along with explanations and provide accessible references for concepts that cannot be covered in the space of a blog post.
(Aside: Beware, LDA is also an abbreviation for Linear Discriminant Analysis a classification technique that I hope to cover later in my ongoing series on text and data analytics).
Latent Dirichlet Allocation – a math-free introduction
In essence, LDA is a technique that facilitates the automatic discovery of themes in a collection of documents.
The basic assumption behind LDA is that each of the documents in a collection consist of a mixture of collection-wide topics. However, in reality we observe only documents and words, not topics – the latter are part of the hidden (or latent) structure of documents. The aim is to infer the latent topic structure given the words and document. LDA does this by recreating the documents in the corpus by adjusting the relative importance of topics in documents and words in topics iteratively.
Here’s a brief explanation of how the algorithm works, quoted directly from this answer by Edwin Chen on Quora:
- Go through each document, and randomly assign each word in the document to one of the K topics. (Note: One of the shortcomings of LDA is that one has to specify the number of topics, denoted by K, upfront. More about this later.)
- This assignment already gives you both topic representations of all the documents and word distributions of all the topics (albeit not very good ones).
- So to improve on them, for each document d…
- ….Go through each word w in d…
- ……..And for each topic t, compute two things: 1) p(topic t | document d) = the proportion of words in document d that are currently assigned to topic t, and 2) p(word w | topic t) = the proportion of assignments to topic t over all documents that come from this word w. Reassign w a new topic, where you choose topic t with probability p(topic t | document d) * p(word w | topic t) (according to our generative model, this is essentially the probability that topic t generated word w, so it makes sense that we resample the current word’s topic with this probability). (Note: p(a|b) is the conditional probability of a given that b has already occurred – see this post for more on conditional probabilities)
- ……..In other words, in this step, we’re assuming that all topic assignments except for the current word in question are correct, and then updating the assignment of the current word using our model of how documents are generated.
- After repeating the previous step a large number of times, you’ll eventually reach a roughly steady state where your assignments are pretty good. So use these assignments to estimate the topic mixtures of each document (by counting the proportion of words assigned to each topic within that document) and the words associated to each topic (by counting the proportion of words assigned to each topic overall).
For another simple explanation of how LDA works in, check out this article by Matthew Jockers. For a more technical exposition, take a look at this video by David Blei, one of the inventors of the algorithm.
The iterative process described in the last point above is implemented using a technique called Gibbs sampling. I’ll say a bit more about Gibbs sampling later, but you may want to have a look at this paper by Philip Resnick and Eric Hardesty that explains the nitty-gritty of the algorithm (Warning: it involves a fair bit of math, but has some good intuitive explanations as well).
As a general point, I should also emphasise that you do not need to understand the ins and outs of an algorithm to use it but it does help to understand, at least at a high level, what the algorithm is doing. One needs to develop a feel for algorithms even if one doesn’t understand the details. Indeed, most people working in analytics do not know the details of the algorithms they use, but that doesn’t stop them from using algorithms intelligently. Purists may disagree. I think they are wrong.
Finally – because you’re no doubt wondering 🙂 – the term “Dirichlet” in LDA refers to the fact that topics and words are assumed to follow Dirichlet distributions. There is no “good” reason for this apart from convenience – Dirichlet distributions provide good approximations to word distributions in documents and, perhaps more important, are computationally convenient.
Preprocessing
As in my previous articles on text mining, I will use a collection of 30 posts from this blog as an example corpus. The corpus can be downloaded here. I will assume that you have R and RStudio installed. Follow this link if you need help with that.
The preprocessing steps are much the same as described in my previous articles. Nevertheless, I’ll risk boring you with a detailed listing so that you can reproduce my results yourself:
docs <- tm_map(docs, toSpace, “-“)
docs <- tm_map(docs, toSpace, “’”)
docs <- tm_map(docs, toSpace, “‘”)
docs <- tm_map(docs, toSpace, “•”)
docs <- tm_map(docs, toSpace, “””)
docs <- tm_map(docs, toSpace, ““”)
pattern = “organiz”, replacement = “organ”)
docs <- tm_map(docs, content_transformer(gsub),
pattern = “organis”, replacement = “organ”)
docs <- tm_map(docs, content_transformer(gsub),
pattern = “andgovern”, replacement = “govern”)
docs <- tm_map(docs, content_transformer(gsub),
pattern = “inenterpris”, replacement = “enterpris”)
docs <- tm_map(docs, content_transformer(gsub),
pattern = “team-“, replacement = “team”)
“also”,”howev”,”tell”,”will”,
“much”,”need”,”take”,”tend”,”even”,
“like”,”particular”,”rather”,”said”,
“get”,”well”,”make”,”ask”,”come”,”end”,
“first”,”two”,”help”,”often”,”may”,
“might”,”see”,”someth”,”thing”,”point”,
“post”,”look”,”right”,”now”,”think”,”‘ve “,
“‘re “,”anoth”,”put”,”set”,”new”,”good”,
“want”,”sure”,”kind”,”larg”,”yes,”,”day”,”etc”,
“quit”,”sinc”,”attempt”,”lack”,”seen”,”awar”,
“littl”,”ever”,”moreov”,”though”,”found”,”abl”,
“enough”,”far”,”earli”,”away”,”achiev”,”draw”,
“last”,”never”,”brief”,”bit”,”entir”,”brief”,
“great”,”lot”)
write.csv(freq[ord],”word_freq.csv”)
Check out the preprocessing section in either this article or this one for detailed explanations of the code. The document term matrix (DTM) produced by the above code will be the main input into the LDA algorithm of the next section.
Topic modelling using LDA
We are now ready to do some topic modelling. We’ll use the topicmodels package written by Bettina Gruen and Kurt Hornik. Specifically, we’ll use the LDA function with the Gibbs sampling option mentioned earlier, and I’ll say more about it in a second. The LDA function has a fairly large number of parameters. I’ll describe these briefly below. For more, please check out this vignette by Gruen and Hornik.
For the most part, we’ll use the default parameter values supplied by the LDA function,custom setting only the parameters that are required by the Gibbs sampling algorithm.
Gibbs sampling works by performing a random walk in such a way that reflects the characteristics of a desired distribution. Because the starting point of the walk is chosen at random, it is necessary to discard the first few steps of the walk (as these do not correctly reflect the properties of distribution). This is referred to as the burn-in period. We set the burn-in parameter to 4000. Following the burn-in period, we perform 2000 iterations, taking every 500th iteration for further use. The reason we do this is to avoid correlations between samples. We use 5 different starting points (nstart=5) – that is, five independent runs. Each starting point requires a seed integer (this also ensures reproducibility), so I have provided 5 random integers in my seed list. Finally I’ve set best to TRUE (actually a default setting), which instructs the algorithm to return results of the run with the highest posterior probability.
Some words of caution are in order here. It should be emphasised that the settings above do not guarantee the convergence of the algorithm to a globally optimal solution. Indeed, Gibbs sampling will, at best, find only a locally optimal solution, and even this is hard to prove mathematically in specific practical problems such as the one we are dealing with here. The upshot of this is that it is best to do lots of runs with different settings of parameters to check the stability of your results. The bottom line is that our interest is purely practical so it is good enough if the results make sense. We’ll leave issues of mathematical rigour to those better qualified to deal with them 🙂
As mentioned earlier, there is an important parameter that must be specified upfront: k, the number of topics that the algorithm should use to classify documents. There are mathematical approaches to this, but they often do not yield semantically meaningful choices of k (see this post on stackoverflow for an example). From a practical point of view, one can simply run the algorithm for different values of k and make a choice based by inspecting the results. This is what we’ll do.
OK, so the first step is to set these parameters in R… and while we’re at it, let’s also load the topicmodels library (Note: you might need to install this package as it is not a part of the base R installation).
iter <- 2000
thin <- 500
seed <-list(2003,5,63,100001,765)
nstart <- 5
best <- TRUE
That done, we can now do the actual work – run the topic modelling algorithm on our corpus. Here is the code:
write.csv(ldaOut.topics,file=paste(“LDAGibbs”,k,”DocsToTopics.csv”))
write.csv(ldaOut.terms,file=paste(“LDAGibbs”,k,”TopicsToTerms.csv”))
write.csv(topicProbabilities,file=paste(“LDAGibbs”,k,”TopicProbabilities.csv”))
sort(topicProbabilities[x,])[k]/sort(topicProbabilities[x,])[k-1])
sort(topicProbabilities[x,])[k-1]/sort(topicProbabilities[x,])[k-2])
write.csv(topic2ToTopic3,file=paste(“LDAGibbs”,k,”Topic2ToTopic3.csv”))
The LDA algorithm returns an object that contains a lot of information. Of particular interest to us are the document to topic assignments, the top terms in each topic and the probabilities associated with each of those terms. These are printed out in the first three calls to write.csv above. There are a few important points to note here:
- Each document is considered to be a mixture of all topics (5 in this case). The assignments in the first file list the top topic – that is, the one with the highest probability (more about this in point 3 below).
- Each topic contains all terms (words) in the corpus, albeit with different probabilities. We list only the top 6 terms in the second file.
- The last file lists the probabilities with which each topic is assigned to a document. This is therefore a 30 x 5 matrix – 30 docs and 5 topics. As one might expect, the highest probability in each row corresponds to the topic assigned to that document. The “goodness” of the primary assignment (as discussed in point 1) can be assessed by taking the ratio of the highest to second-highest probability and the second-highest to the third-highest probability and so on. This is what I’ve done in the last nine lines of the code above.
Take some time to examine the output and confirm for yourself that that the primary topic assignments are best when the ratios of probabilities discussed in point 3 are highest. You should also experiment with different values of k to see if you can find better topic distributions. In the interests of space I will restrict myself to k = 5.
The table below lists the top 6 terms in topics 1 through 5.
| Topic 1 | Topic 2 | Topic 3 | Topic 4 | Topic 5 | |
| 1 | work | question | chang | system | project |
| 2 | practic | map | organ | data | manag |
| 3 | mani | time | consult | model | approach |
| 4 | flexibl | ibi | manag | design | organ |
| 5 | differ | issu | work | process | decis |
| 6 | best | plan | problem | busi | problem |
The table below lists the document to (primary) topic assignments:
| Document | Topic |
| BeyondEntitiesAndRelationships.txt | 4 |
| bigdata.txt | 4 |
| ConditionsOverCauses.txt | 5 |
| EmergentDesignInEnterpriseIT.txt | 4 |
| FromInformationToKnowledge.txt | 2 |
| FromTheCoalface.txt | 1 |
| HeraclitusAndParmenides.txt | 3 |
| IroniesOfEnterpriseIT.txt | 3 |
| MakingSenseOfOrganizationalChange.txt | 5 |
| MakingSenseOfSensemaking.txt | 2 |
| ObjectivityAndTheEthicalDimensionOfDecisionMaking.txt | 5 |
| OnTheInherentAmbiguitiesOfManagingProjects.txt | 5 |
| OrganisationalSurprise.txt | 5 |
| ProfessionalsOrPoliticians.txt | 3 |
| RitualsInInformationSystemDesign.txt | 4 |
| RoutinesAndReality.txt | 4 |
| ScapegoatsAndSystems.txt | 5 |
| SherlockHolmesFailedProjects.txt | 3 |
| sherlockHolmesMgmtFetis.txt | 3 |
| SixHeresiesForBI.txt | 4 |
| SixHeresiesForEnterpriseArchitecture.txt | 3 |
| TheArchitectAndTheApparition.txt | 3 |
| TheCloudAndTheGrass.txt | 2 |
| TheConsultantsDilemma.txt | 3 |
| TheDangerWithin.txt | 5 |
| TheDilemmasOfEnterpriseIT.txt | 3 |
| TheEssenceOfEntrepreneurship.txt | 1 |
| ThreeTypesOfUncertainty.txt | 5 |
| TOGAFOrNotTOGAF.txt | 3 |
| UnderstandingFlexibility.txt | 1 |
From a quick perusal of the two tables it appears that the algorithm has done a pretty decent job. For example,topic 4 is about data and system design, and the documents assigned to it are on topic. However, it is far from perfect – for example, the interview I did with Neil Preston on organisational change (MakingSenseOfOrganizationalChange.txt) has been assigned to topic 5, which seems to be about project management. It ought to be associated with Topic 3, which is about change. Let’s see if we can resolve this by looking at probabilities associated with topics.
The table below lists the topic probabilities by document:
| Topic 1 | Topic 2 | Topic 3 | Topic 4 | Topic 5 | |
| BeyondEn | 0.071 | 0.064 | 0.024 | 0.741 | 0.1 |
| bigdata. | 0.182 | 0.221 | 0.182 | 0.26 | 0.156 |
| Conditio | 0.144 | 0.109 | 0.048 | 0.205 | 0.494 |
| Emergent | 0.121 | 0.226 | 0.204 | 0.236 | 0.213 |
| FromInfo | 0.096 | 0.643 | 0.026 | 0.169 | 0.066 |
| FromTheC | 0.636 | 0.082 | 0.058 | 0.086 | 0.138 |
| Heraclit | 0.137 | 0.091 | 0.503 | 0.162 | 0.107 |
| IroniesO | 0.101 | 0.088 | 0.388 | 0.26 | 0.162 |
| MakingSe | 0.13 | 0.206 | 0.262 | 0.089 | 0.313 |
| MakingSe | 0.09 | 0.715 | 0.055 | 0.067 | 0.074 |
| Objectiv | 0.216 | 0.078 | 0.086 | 0.242 | 0.378 |
| OnTheInh | 0.18 | 0.234 | 0.102 | 0.12 | 0.364 |
| Organisa | 0.089 | 0.095 | 0.07 | 0.092 | 0.655 |
| Professi | 0.155 | 0.064 | 0.509 | 0.128 | 0.144 |
| RitualsI | 0.103 | 0.064 | 0.044 | 0.676 | 0.112 |
| Routines | 0.108 | 0.042 | 0.033 | 0.69 | 0.127 |
| Scapegoa | 0.135 | 0.088 | 0.043 | 0.185 | 0.549 |
| Sherlock | 0.093 | 0.082 | 0.398 | 0.195 | 0.232 |
| sherlock | 0.108 | 0.136 | 0.453 | 0.123 | 0.18 |
| SixHeres | 0.159 | 0.11 | 0.078 | 0.516 | 0.138 |
| SixHeres | 0.104 | 0.111 | 0.366 | 0.212 | 0.207 |
| TheArchi | 0.111 | 0.221 | 0.522 | 0.088 | 0.058 |
| TheCloud | 0.185 | 0.333 | 0.198 | 0.136 | 0.148 |
| TheConsu | 0.105 | 0.184 | 0.518 | 0.096 | 0.096 |
| TheDange | 0.114 | 0.079 | 0.037 | 0.079 | 0.69 |
| TheDilem | 0.125 | 0.128 | 0.389 | 0.261 | 0.098 |
| TheEssen | 0.713 | 0.059 | 0.031 | 0.113 | 0.084 |
| ThreeTyp | 0.09 | 0.076 | 0.042 | 0.083 | 0.708 |
| TOGAFOrN | 0.158 | 0.232 | 0.352 | 0.151 | 0.107 |
| Understa | 0.658 | 0.065 | 0.072 | 0.101 | 0.105 |
In the table, the highest probability in each row is in bold. Also, in cases where the maximum and the second/third largest probabilities are close, I have highlighted the second (and third) highest probabilities in red. It is clear that Neil’s interview (9th document in the above table) has 3 topics with comparable probabilities – topic 5 (project management), topic 3 (change) and topic 2 (issue mapping / ibis), in decreasing order of probabilities. In general, if a document has multiple topics with comparable probabilities, it simply means that the document speaks to all those topics in proportions indicated by the probabilities. A reading of Neil’s interview will convince you that our conversation did indeed range over all those topics.
That said, the algorithm is far from perfect. You might have already noticed a few poor assignments. Here is one – my post on Sherlock Holmes and the case of the failed project has been assigned to topic 3; I reckon it belongs in topic 5. There are a number of others, but I won’t belabor the point, except to reiterate that this precisely why you definitely want to experiment with different settings of the iteration parameters (to check for stability) and, more important, try a range of different values of k to find the optimal number of topics.
To conclude
Topic modelling provides a quick and convenient way to perform unsupervised classification of a corpus of documents. As always, though, one needs to examine the results carefully to check that they make sense.
I’d like to end with a general observation. Classifying documents is an age-old concern that cuts across disciplines. So it is no surprise that topic modelling has got a look-in from diverse communities. Indeed, when I was reading up and learning about LDA, I found that some of the best introductory articles in the area have been written by academics working in English departments! This is one of the things I love about working in text analysis, there is a wealth of material on the web written from diverse perspectives. The term cross-disciplinary often tends to be a platitude , but in this case it is simply a statement of fact.
I hope that I have been able to convince you to explore this rapidly evolving field. Exciting times ahead, come join the fun.
A gentle introduction to cluster analysis using R
Introduction
Welcome to the second part of my introductory series on text analysis using R (the first article can be accessed here). My aim in the present piece is to provide a practical introduction to cluster analysis. I’ll begin with some background before moving on to the nuts and bolts of clustering. We have a fair bit to cover, so let’s get right to it.
A common problem when analysing large collections of documents is to categorize them in some meaningful way. This is easy enough if one has a predefined classification scheme that is known to fit the collection (and if the collection is small enough to be browsed manually). One can then simply scan the documents, looking for keywords appropriate to each category and classify the documents based on the results. More often than not, however, such a classification scheme is not available and the collection too large. One then needs to use algorithms that can classify documents automatically based on their structure and content.
The present post is a practical introduction to a couple of automatic text categorization techniques, often referred to as clustering algorithms. As the Wikipedia article on clustering tells us:
Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar (in some sense or another) to each other than to those in other groups (clusters).
As one might guess from the above, the results of clustering depend rather critically on the method one uses to group objects. Again, quoting from the Wikipedia piece:
Cluster analysis itself is not one specific algorithm, but the general task to be solved. It can be achieved by various algorithms that differ significantly in their notion of what constitutes a cluster and how to efficiently find them. Popular notions of clusters include groups with small distances [Note: we’ll use distance-based methods] among the cluster members, dense areas of the data space, intervals or particular statistical distributions [i.e. distributions of words within documents and the entire collection].
…and a bit later:
…the notion of a “cluster” cannot be precisely defined, which is one of the reasons why there are so many clustering algorithms. There is a common denominator: a group of data objects. However, different researchers employ different cluster models, and for each of these cluster models again different algorithms can be given. The notion of a cluster, as found by different algorithms, varies significantly in its properties. Understanding these “cluster models” is key to understanding the differences between the various algorithms.
An upshot of the above is that it is not always straightforward to interpret the output of clustering algorithms. Indeed, we will see this in the example discussed below.
With that said for an introduction, let’s move on to the nut and bolts of clustering.
Preprocessing the corpus
In this section I cover the steps required to create the R objects necessary in order to do clustering. It goes over territory that I’ve covered in detail in the first article in this series – albeit with a few tweaks, so you may want to skim through even if you’ve read my previous piece.
To begin with I’ll assume you have R and RStudio (a free development environment for R) installed on your computer and are familiar with the basic functionality in the text mining ™ package. If you need help with this, please look at the instructions in my previous article on text mining.
As in the first part of this series, I will use 30 posts from my blog as the example collection (or corpus, in text mining-speak). The corpus can be downloaded here. For completeness, I will run through the entire sequence of steps – right from loading the corpus into R, to running the two clustering algorithms.
Ready? Let’s go…
The first step is to fire up RStudio and navigate to the directory in which you have unpacked the example corpus. Once this is done, load the text mining package, tm. Here’s the relevant code (Note: a complete listing of the code in this article can be accessed here):
[1] “C:/Users/Kailash/Documents”
#set working directory – fix path as needed!
setwd(“C:/Users/Kailash/Documents/TextMining”)
#load tm library
library(tm)
Loading required package: NLP
Note: R commands are in blue, output in black or red; lines that start with # are comments.
If you get an error here, you probably need to download and install the tm package. You can do this in RStudio by going to Tools > Install Packages and entering “tm”. When installing a new package, R automatically checks for and installs any dependent packages.
The next step is to load the collection of documents into an object that can be manipulated by functions in the tm package.
docs <- Corpus(DirSource("C:/Users/Kailash/Documents/TextMining"))
#inspect a particular document
writeLines(as.character(docs[[30]]))
…
The next step is to clean up the corpus. This includes things such as transforming to a consistent case, removing non-standard symbols & punctuation, and removing numbers (assuming that numbers do not contain useful information, which is the case here):
docs <- tm_map(docs,content_transformer(tolower))
#remove potentiallyy problematic symbols
toSpace <- content_transformer(function(x, pattern) { return (gsub(pattern, " ", x))})
docs <- tm_map(docs, toSpace, "-")
docs <- tm_map(docs, toSpace, ":")
docs <- tm_map(docs, toSpace, "‘")
docs <- tm_map(docs, toSpace, "•")
docs <- tm_map(docs, toSpace, "• ")
docs <- tm_map(docs, toSpace, " -")
docs <- tm_map(docs, toSpace, "“")
docs <- tm_map(docs, toSpace, "”")
#remove punctuation
docs <- tm_map(docs, removePunctuation)
#Strip digits
docs <- tm_map(docs, removeNumbers)
Note: please see my previous article for more on content_transformer and the toSpace function defined above.
Next we remove stopwords – common words (like “a” “and” “the”, for example) and eliminate extraneous whitespaces.
docs <- tm_map(docs, removeWords, stopwords("english"))
#remove whitespace
docs <- tm_map(docs, stripWhitespace)
writeLines(as.character(docs[[30]]))
flexibility eye beholder action increase organisational flexibility say redeploying employees likely seen affected move constrains individual flexibility dual meaning characteristic many organizational platitudes excellence synergy andgovernance interesting exercise analyse platitudes expose difference espoused actual meanings sign wishing many hours platitude deconstructing fun
At this point it is critical to inspect the corpus because stopword removal in tm can be flaky. Yes, this is annoying but not a showstopper because one can remove problematic words manually once one has identified them – more about this in a minute.
Next, we stem the document – i.e. truncate words to their base form. For example, “education”, “educate” and “educative” are stemmed to “educat.”:
Stemming works well enough, but there are some fixes that need to be done due to my inconsistent use of British/Aussie and US English. Also, we’ll take this opportunity to fix up some concatenations like “andgovernance” (see paragraph printed out above). Here’s the code:
docs <- tm_map(docs, content_transformer(gsub), pattern = "organis", replacement = "organ")
docs <- tm_map(docs, content_transformer(gsub), pattern = "andgovern", replacement = "govern")
docs <- tm_map(docs, content_transformer(gsub), pattern = "inenterpris", replacement = "enterpris")
docs <- tm_map(docs, content_transformer(gsub), pattern = "team-", replacement = "team")
The next step is to remove the stopwords that were missed by R. The best way to do this for a small corpus is to go through it and compile a list of words to be eliminated. One can then create a custom vector containing words to be removed and use the removeWords transformation to do the needful. Here is the code (Note: + indicates a continuation of a statement from the previous line):
+ "also","howev","tell","will",
+ "much","need","take","tend","even",
+ "like","particular","rather","said",
+ "get","well","make","ask","come","end",
+ "first","two","help","often","may",
+ "might","see","someth","thing","point",
+ "post","look","right","now","think","’ve ",
+ "’re ")
#remove custom stopwords
docs <- tm_map(docs, removeWords, myStopwords)
Again, it is a good idea to check that the offending words have really been eliminated.
The final preprocessing step is to create a document-term matrix (DTM) – a matrix that lists all occurrences of words in the corpus. In a DTM, documents are represented by rows and the terms (or words) by columns. If a word occurs in a particular document n times, then the matrix entry for corresponding to that row and column is n, if it doesn’t occur at all, the entry is 0.
Creating a DTM is straightforward– one simply uses the built-in DocumentTermMatrix function provided by the tm package like so:
#print a summary
dtmNon-/sparse entries: 13312/110618
Sparsity : 89%
Maximal term length: 48
Weighting : term frequency (tf)
This brings us to the end of the preprocessing phase. Next, I’ll briefly explain how distance-based algorithms work before going on to the actual work of clustering.
An intuitive introduction to the algorithms
As mentioned in the introduction, the basic idea behind document or text clustering is to categorise documents into groups based on likeness. Let’s take a brief look at how the algorithms work their magic.
Consider the structure of the DTM. Very briefly, it is a matrix in which the documents are represented as rows and words as columns. In our case, the corpus has 30 documents and 4131 words, so the DTM is a 30 x 4131 matrix. Mathematically, one can think of this matrix as describing a 4131 dimensional space in which each of the words represents a coordinate axis and each document is represented as a point in this space. This is hard to visualise of course, so it may help to illustrate this via a two-document corpus with only three words in total.
Consider the following corpus:
Document A: “five plus five”
Document B: “five plus six”
These two documents can be represented as points in a 3 dimensional space that has the words “five” “plus” and “six” as the three coordinate axes (see figure 1).

Figure 1: Documents A and B as points in a 3-word space
Now, if each of the documents can be thought of as a point in a space, it is easy enough to take the next logical step which is to define the notion of a distance between two points (i.e. two documents). In figure 1 the distance between A and B (which I denote as 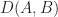
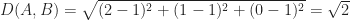
Generalising the above to the 4131 dimensional space at hand, the distance between two documents (let’s call them X and Y) have coordinates (word frequencies) 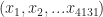


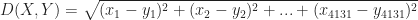
It should be noted that the Euclidean distance that I have described is above is not the only possible way to define distance mathematically. There are many others but it would take me too far afield to discuss them here – see this article for more (and don’t be put off by the term metric, a metric in this context is merely a distance)
What’s important here is the idea that one can define a numerical distance between documents. Once this is grasped, it is easy to understand the basic idea behind how (some) clustering algorithms work – they group documents based on distance-related criteria. To be sure, this explanation is simplistic and glosses over some of the complicated details in the algorithms. Nevertheless it is a reasonable, approximate explanation for what goes on under the hood. I hope purists reading this will agree!
Finally, for completeness I should mention that there are many clustering algorithms out there, and not all of them are distance-based.
Hierarchical clustering
The first algorithm we’ll look at is hierarchical clustering. As the Wikipedia article on the topic tells us, strategies for hierarchical clustering fall into two types:
Agglomerative: where we start out with each document in its own cluster. The algorithm iteratively merges documents or clusters that are closest to each other until the entire corpus forms a single cluster. Each merge happens at a different (increasing) distance.
Divisive: where we start out with the entire set of documents in a single cluster. At each step the algorithm splits the cluster recursively until each document is in its own cluster. This is basically the inverse of an agglomerative strategy.
The algorithm we’ll use is hclust which does agglomerative hierarchical clustering. Here’s a simplified description of how it works:
- Assign each document to its own (single member) cluster
- Find the pair of clusters that are closest to each other and merge them. So you now have one cluster less than before.
- Compute distances between the new cluster and each of the old clusters.
- Repeat steps 2 and 3 until you have a single cluster containing all documents.
We’ll need to do a few things before running the algorithm. Firstly, we need to convert the DTM into a standard matrix which can be used by dist, the distance computation function in R (the DTM is not stored as a standard matrix). We’ll also shorten the document names so that they display nicely in the graph that we will use to display results of hclust (the names I have given the documents are just way too long). Here’s the relevant code:
m <- as.matrix(dtm)
#write as csv file (optional)
write.csv(m,file="dtmEight2Late.csv")
#shorten rownames for display purposes
rownames(m) <- paste(substring(rownames(m),1,3),rep("..",nrow(m)),
+ substring(rownames(m), nchar(rownames(m))-12,nchar(rownames(m))-4))
#compute distance between document vectors
d <- dist(m)
Next we run hclust. The algorithm offers several options check out the documentation for details. I use a popular option called Ward’s method – there are others, and I suggest you experiment with them as each of them gives slightly different results making interpretation somewhat tricky (did I mention that clustering is as much an art as a science??). Finally, we visualise the results in a dendogram (see Figure 2 below).
#run hierarchical clustering using Ward’s method
groups <- hclust(d,method="ward.D")
#plot dendogram, use hang to ensure that labels fall below tree
plot(groups, hang=-1)

Figure 2: Dendogram from hierarchical clustering of corpus
A few words on interpreting dendrograms for hierarchical clusters: as you work your way down the tree in figure 2, each branch point you encounter is the distance at which a cluster merge occurred. Clearly, the most well-defined clusters are those that have the largest separation; many closely spaced branch points indicate a lack of dissimilarity (i.e. distance, in this case) between clusters. Based on this, the figure reveals that there are 2 well-defined clusters – the first one consisting of the three documents at the right end of the cluster and the second containing all other documents. We can display the clusters on the graph using the rect.hclust function like so:
rect.hclust(groups,2)
The result is shown in the figure below.

Figure 3: 2 cluster grouping
The figures 4 and 5 below show the grouping for 3, and 5 clusters.

Figure 4: 3 cluster grouping

Figure 5: 5 cluster grouping
I’ll make just one point here: the 2 cluster grouping seems the most robust one as it happens at large distance, and is cleanly separated (distance-wise) from the 3 and 5 cluster grouping. That said, I’ll leave you to explore the ins and outs of hclust on your own and move on to our next algorithm.
K means clustering
In hierarchical clustering we did not specify the number of clusters upfront. These were determined by looking at the dendogram after the algorithm had done its work. In contrast, our next algorithm – K means – requires us to define the number of clusters upfront (this number being the “k” in the name). The algorithm then generates k document clusters in a way that ensures the within-cluster distances from each cluster member to the centroid (or geometric mean) of the cluster is minimised.
Here’s a simplified description of the algorithm:
- Assign the documents randomly to k bins
- Compute the location of the centroid of each bin.
- Compute the distance between each document and each centroid
- Assign each document to the bin corresponding to the centroid closest to it.
- Stop if no document is moved to a new bin, else go to step 2.
An important limitation of the k means method is that the solution found by the algorithm corresponds to a local rather than global minimum (this figure from Wikipedia explains the difference between the two in a nice succinct way). As a consequence it is important to run the algorithm a number of times (each time with a different starting configuration) and then select the result that gives the overall lowest sum of within-cluster distances for all documents. A simple check that a solution is robust is to run the algorithm for an increasing number of initial configurations until the result does not change significantly. That said, this procedure does not guarantee a globally optimal solution.
I reckon that’s enough said about the algorithm, let’s get on with it using it. The relevant function, as you might well have guessed is kmeans. As always, I urge you to check the documentation to understand the available options. We’ll use the default options for all parameters excepting nstart which we set to 100. We also plot the result using the clusplot function from the cluster library (which you may need to install. Reminder you can install packages via the Tools>Install Packages menu in RStudio)
kfit <- kmeans(d, 2, nstart=100)
#plot – need library cluster
library(cluster)
clusplot(as.matrix(d), kfit$cluster, color=T, shade=T, labels=2, lines=0)
The plot is shown in Figure 6.

Figure 6: principal component plot (k=2)
The cluster plot shown in the figure above needs a bit of explanation. As mentioned earlier, the clustering algorithms work in a mathematical space whose dimensionality equals the number of words in the corpus (4131 in our case). Clearly, this is impossible to visualize. To handle this, mathematicians have invented a dimensionality reduction technique called Principal Component Analysis which reduces the number of dimensions to 2 (in this case) in such a way that the reduced dimensions capture as much of the variability between the clusters as possible (and hence the comment, “these two components explain 69.42% of the point variability” at the bottom of the plot in figure 6)
(Aside Yes I realize the figures are hard to read because of the overly long names, I leave it to you to fix that. No excuses, you know how…:-))
Running the algorithm and plotting the results for k=3 and 5 yields the figures below.

Figure 7: Principal component plot (k=3)

Figure 8: Principal component plot (k=5)
Choosing k
Recall that the k means algorithm requires us to specify k upfront. A natural question then is: what is the best choice of k? In truth there is no one-size-fits-all answer to this question, but there are some heuristics that might sometimes help guide the choice. For completeness I’ll describe one below even though it is not much help in our clustering problem.
In my simplified description of the k means algorithm I mentioned that the technique attempts to minimise the sum of the distances between the points in a cluster and the cluster’s centroid. Actually, the quantity that is minimised is the total of the within-cluster sum of squares (WSS) between each point and the mean. Intuitively one might expect this quantity to be maximum when k=1 and then decrease as k increases, sharply at first and then less sharply as k reaches its optimal value.
The problem with this reasoning is that it often happens that the within cluster sum of squares never shows a slowing down in decrease of the summed WSS. Unfortunately this is exactly what happens in the case at hand.
I reckon a picture might help make the above clearer. Below is the R code to draw a plot of summed WSS as a function of k for k=2 all the way to 29 (1-total number of documents):
#look for “elbow” in plot of summed intra-cluster distances (withinss) as fn of k
wss <- 2:29
for (i in 2:29) wss[i] <- sum(kmeans(d,centers=i,nstart=25)$withinss)
plot(2:29, wss[2:29], type="b", xlab="Number of Clusters",ylab="Within groups sum of squares")
…and the figure below shows the resulting plot.

Figure 10: WSS as a function of k (“elbow plot”)
The plot clearly shows that there is no k for which the summed WSS flattens out (no distinct “elbow”). As a result this method does not help. Fortunately, in this case one can get a sensible answer using common sense rather than computation: a choice of 2 clusters seems optimal because both algorithms yield exactly the same clusters and show the clearest cluster separation at this point (review the dendogram and cluster plots for k=2).
The meaning of it all
Now I must acknowledge an elephant in the room that I have steadfastly ignored thus far. The odds are good that you’ve seen it already….
It is this: what topics or themes do the (two) clusters correspond to?
Unfortunately this question does not have a straightforward answer. Although the algorithms suggest a 2-cluster grouping, they are silent on the topics or themes related to these. Moreover, as you will see if you experiment, the results of clustering depend on:
- The criteria for the construction of the DTM (see the documentation for DocumentTermMatrix for options).
- The clustering algorithm itself.
Indeed, insofar as clustering is concerned, subject matter and corpus knowledge is the best way to figure out cluster themes. This serves to reinforce (yet again!) that clustering is as much an art as it is a science.
In the case at hand, article length seems to be an important differentiator between the 2 clusters found by both algorithms. The three articles in the smaller cluster are in the top 4 longest pieces in the corpus. Additionally, the three pieces are related to sensemaking and dialogue mapping. There are probably other factors as well, but none that stand out as being significant. I should mention, however, that the fact that article length seems to play a significant role here suggests that it may be worth checking out the effect of scaling distances by word counts or using other measures such a cosine similarity – but that’s a topic for another post! (Note added on Dec 3 2015: check out my article on visualizing relationships between documents using network graphs for a detailed discussion on cosine similarity)
The take home lesson is that is that the results of clustering are often hard to interpret. This should not be surprising – the algorithms cannot interpret meaning, they simply chug through a mathematical optimisation problem. The onus is on the analyst to figure out what it means…or if it means anything at all.
Conclusion
This brings us to the end of a long ramble through clustering. We’ve explored the two most common methods: hierarchical and k means clustering (there are many others available in R, and I urge you to explore them). Apart from providing the detailed steps to do clustering, I have attempted to provide an intuitive explanation of how the algorithms work. I hope I have succeeded in doing so. As always your feedback would be very welcome.
Finally, I’d like to reiterate an important point: the results of our clustering exercise do not have a straightforward interpretation, and this is often the case in cluster analysis. Fortunately I can close on an optimistic note. There are other text mining techniques that do a better job in grouping documents based on topics and themes rather than word frequencies alone. I’ll discuss this in the next article in this series. Until then, I wish you many enjoyable hours exploring the ins and outs of clustering.
Note added on September 29th 2015:
If you liked this article, you might want to check out its sequel – an introduction to topic modeling.
A gentle introduction to text mining using R
Preamble
This article is based on my exploration of the basic text mining capabilities of R, the open source statistical software. It is intended primarily as a tutorial for novices in text mining as well as R. However, unlike conventional tutorials, I spend a good bit of time setting the context by describing the problem that led me to text mining and thence to R. I also talk about the limitations of the techniques I describe, and point out directions for further exploration for those who are interested. Indeed, I’ll likely explore some of these myself in future articles.
If you have no time and /or wish to cut to the chase, please go straight to the section entitled, Preliminaries – installing R and RStudio. If you have already installed R and have worked with it, you may want to stop reading as I doubt there’s anything I can tell you that you don’t already know 🙂
A couple of warnings are in order before we proceed. R and the text mining options we explore below are open source software. Version differences in open source can be significant and are not always documented in a way that corporate IT types are used to. Indeed, I was tripped up by such differences in an earlier version of this article (now revised). So, just for the record, the examples below were run on version 3.2.0 of R and version 0.6-1 of the tm (text mining) package for R. A second point follows from this: as is evident from its version number, the tm package is still in the early stages of its evolution. As a result – and we will see this below – things do not always work as advertised. So assume nothing, and inspect the results in detail at every step. Be warned that I do not always do this below, as my aim is introduction rather than accuracy.
Background and motivation
Traditional data analysis is based on the relational model in which data is stored in tables. Within tables, data is stored in rows – each row representing a single record of an entity of interest (such as a customer or an account). The columns represent attributes of the entity. For example, the customer table might consist of columns such as name, street address, city, postcode, telephone number . Typically these are defined upfront, when the data model is created. It is possible to add columns after the fact, but this tends to be messy because one also has to update existing rows with information pertaining to the added attribute.
As long as one asks for information that is based only on existing attributes – an example being, “give me a list of customers based in Sydney” – a database analyst can use Structured Query Language (the defacto language of relational databases ) to get an answer. A problem arises, however, if one asks for information that is based on attributes that are not included in the database. An example in the above case would be: “give me a list of customers who have made a complaint in the last twelve months.”
As a result of the above, many data modelers will include a “catch-all” free text column that can be used to capture additional information in an ad-hoc way. As one might imagine, this column will often end up containing several lines, or even paragraphs of text that are near impossible to analyse with the tools available in relational databases.
(Note: for completeness I should add that most database vendors have incorporated text mining capabilities into their products. Indeed, many of them now include R…which is another good reason to learn it.)
My story
Over the last few months, when time permits, I’ve been doing an in-depth exploration of the data captured by my organisation’s IT service management tool. Such tools capture all support tickets that are logged, and track their progress until they are closed. As it turns out, there are a number of cases where calls are logged against categories that are too broad to be useful – the infamous catch-all category called “Unknown.” In such cases, much of the important information is captured in a free text column, which is difficult to analyse unless one knows what one is looking for. The problem I was grappling with was to identify patterns and hence define sub-categories that would enable support staff to categorise these calls meaningfully.
One way to do this is to guess what the sub-categories might be…and one can sometimes make pretty good guesses if one knows the data well enough. In general, however, guessing is a terrible strategy because one does not know what one does not know. The only sensible way to extract subcategories is to analyse the content of the free text column systematically. This is a classic text mining problem.
Now, I knew a bit about the theory of text mining, but had little practical experience with it. So the logical place for me to start was to look for a suitable text mining tool. Our vendor (who shall remain unnamed) has a “Rolls-Royce” statistical tool that has a good text mining add-on. We don’t have licenses for the tool, but the vendor was willing to give us a trial license for a few months…with the understanding that this was on an intent-to-purchase basis.
I therefore started looking at open source options. While doing so, I stumbled on an interesting paper by Ingo Feinerer that describes a text mining framework for the R environment. Now, I knew about R, and was vaguely aware that it offered text mining capabilities, but I’d not looked into the details. Anyway, I started reading the paper…and kept going until I finished.
As I read, I realised that this could be the answer to my problems. Even better, it would not require me trade in assorted limbs for a license.
I decided to give it a go.
Preliminaries – installing R and RStudio
R can be downloaded from the R Project website. There is a Windows version available, which installed painlessly on my laptop. Commonly encountered installation issues are answered in the (very helpful) R for Windows FAQ.
RStudio is an integrated development environment (IDE) for R. There is a commercial version of the product, but there is also a free open source version. In what follows, I’ve used the free version. Like R, RStudio installs painlessly and also detects your R installation.
RStudio has the following panels:
- A script editor in which you can create R scripts (top left). You can also open a new script editor window by going to File > New File > RScript.
- The console where you can execute R commands/scripts (bottom left)
- Environment and history (top right)
- Files in the current working directory, installed R packages, plots and a help display screen (bottom right).
Check out this short video for a quick introduction to RStudio.
You can access help anytime (within both R and RStudio) by typing a question mark before a command. Exercise: try this by typing ?getwd() and ?setwd() in the console.
I should reiterate that the installation process for both products was seriously simple…and seriously impressive. “Rolls-Royce” business intelligence vendors could take a lesson from that…in addition to taking a long hard look at the ridiculous prices they charge.
There is another small step before we move on to the fun stuff. Text mining and certain plotting packages are not installed by default so one has to install them manually The relevant packages are:
- tm – the text mining package (see documentation). Also check out this excellent introductory article on tm.
- SnowballC – required for stemming (explained below).
- ggplot2 – plotting capabilities (see documentation)
- wordcloud – which is self-explanatory (see documentation) .
(Warning for Windows users: R is case-sensitive so Wordcloud != wordcloud)
The simplest way to install packages is to use RStudio’s built in capabilities (go to Tools > Install Packages in the menu). If you’re working on Windows 7 or 8, you might run into a permissions issue when installing packages. If you do, you might find this advice from the R for Windows FAQ helpful.
Preliminaries – The example dataset
The data I had from our service management tool isn’t the best dataset to learn with as it is quite messy. But then, I have a reasonable data source in my virtual backyard: this blog. To this end, I converted all posts I’ve written since Dec 2013 into plain text form (30 posts in all). You can download the zip file of these here .
I suggest you create a new folder called – called, say, TextMining – and unzip the files in that folder.
That done, we’re good to start…
Preliminaries – Basic Navigation
A few things to note before we proceed:
- In what follows, I enter the commands directly in the console. However, here’s a little RStudio tip that you may want to consider: you can enter an R command or code fragment in the script editor and then hit Ctrl-Enter (i.e. hit the Enter key while holding down the Control key) to copy the line to the console. This will enable you to save the script as you go along.
- In the code snippets below, the functions / commands to be typed in the R console are in blue font. The output is in black. I will also denote references to functions / commands in the body of the article by italicising them as in “setwd()”. Be aware that I’ve omitted the command prompt “>” in the code snippets below!
- It is best not to cut-n-paste commands directly from the article as quotes are sometimes not rendered correctly. A text file of all the code in this article is available here.
The > prompt in the RStudio console indicates that R is ready to process commands.
To see the current working directory type in getwd() and hit return. You’ll see something like:
[1] “C:/Users/Documents”
The exact output will of course depend on your working directory. Note the forward slashes in the path. This is because of R’s Unix heritage (backslash is an escape character in R.). So, here’s how would change the working directory to C:\Users:
You can now use getwd()to check that setwd() has done what it should.
[1]”C:/Users”
I won’t say much more here about R as I want to get on with the main business of the article. Check out this very short introduction to R for a quick crash course.
Loading data into R
Start RStudio and open the TextMining project you created earlier.
The next step is to load the tm package as this is not loaded by default. This is done using the library() function like so:
Dependent packages are loaded automatically – in this case the dependency is on the NLP (natural language processing) package.
Next, we need to create a collection of documents (technically referred to as a Corpus) in the R environment. This basically involves loading the files created in the TextMining folder into a Corpus object. The tm package provides the Corpus() function to do this. There are several ways to create a Corpus (check out the online help using ? as explained earlier). In a nutshell, the Corpus() function can read from various sources including a directory. That’s the option we’ll use:
docs <- Corpus(DirSource(“C:/Users/Kailash/Documents/TextMining”))
At the risk of stating the obvious, you will need to tailor this path as appropriate.
A couple of things to note in the above. Any line that starts with a # is a comment, and the “<-“ tells R to assign the result of the command on the right hand side to the variable on the left hand side. In this case the Corpus object created is stored in a variable called docs. One can also use the equals sign (=) for assignment if one wants to.
Type in docs to see some information about the newly created corpus:
Metadata: corpus specific: 0, document level (indexed): 0
Content: documents: 30
The summary() function gives more details, including a complete listing of files…but it isn’t particularly enlightening. Instead, we’ll examine a particular document in the corpus.
writeLines(as.character(docs[[30]]))
Which prints the entire content of 30th document in the corpus to the console.
Pre-processing
Data cleansing, though tedious, is perhaps the most important step in text analysis. As we will see, dirty data can play havoc with the results. Furthermore, as we will also see, data cleaning is invariably an iterative process as there are always problems that are overlooked the first time around.
The tm package offers a number of transformations that ease the tedium of cleaning data. To see the available transformations type getTransformations() at the R prompt:
> getTransformations()
[1] “removeNumbers” “removePunctuation” “removeWords” “stemDocument” “stripWhitespace”
Most of these are self-explanatory. I’ll explain those that aren’t as we go along.
There are a few preliminary clean-up steps we need to do before we use these powerful transformations. If you inspect some documents in the corpus (and you know how to do that now), you will notice that I have some quirks in my writing. For example, I often use colons and hyphens without spaces between the words separated by them. Using the removePunctuation transform without fixing this will cause the two words on either side of the symbols to be combined. Clearly, we need to fix this prior to using the transformations.
To fix the above, one has to create a custom transformation. The tm package provides the ability to do this via the content_transformer function. This function takes a function as input, the input function should specify what transformation needs to be done. In this case, the input function would be one that replaces all instances of a character by spaces. As it turns out the gsub() function does just that.
Here is the R code to build the content transformer, which we will call toSpace:
Now we can use this content transformer to eliminate colons and hypens like so:
docs <- tm_map(docs, toSpace, “:”)
Inspect random sections f corpus to check that the result is what you intend (use writeLines as shown earlier). To reiterate something I mentioned in the preamble, it is good practice to inspect the a subset of the corpus after each transformation.
If it all looks good, we can now apply the removePunctuation transformation. This is done as follows:
Inspecting the corpus reveals that several “non-standard” punctuation marks have not been removed. These include the single curly quote marks and a space-hyphen combination. These can be removed using our custom content transformer, toSpace. Note that you might want to copy-n-paste these symbols directly from the relevant text file to ensure that they are accurately represented in toSpace.
docs <- tm_map(docs, toSpace, “‘”)
docs <- tm_map(docs, toSpace, ” -“)
Inspect the corpus again to ensure that the offenders have been eliminated. This is also a good time to check for any other special symbols that may need to be removed manually.
If all is well, you can move to the next step which is to:
- Convert the corpus to lower case
- Remove all numbers.
Since R is case sensitive, “Text” is not equal to “text” – and hence the rationale for converting to a standard case. However, although there is a tolower transformation, it is not a part of the standard tm transformations (see the output of getTransformations() in the previous section). For this reason, we have to convert tolower into a transformation that can handle a corpus object properly. This is done with the help of our new friend, content_transformer.
Here’s the relevant code:
docs <- tm_map(docs,content_transformer(tolower))
Text analysts are typically not interested in numbers since these do not usually contribute to the meaning of the text. However, this may not always be so. For example, it is definitely not the case if one is interested in getting a count of the number of times a particular year appears in a corpus. This does not need to be wrapped in content_transformer as it is a standard transformation in tm.
docs <- tm_map(docs, removeNumbers)
Once again, be sure to inspect the corpus before proceeding.
The next step is to remove common words from the text. These include words such as articles (a, an, the), conjunctions (and, or but etc.), common verbs (is), qualifiers (yet, however etc) . The tm package includes a standard list of such stop words as they are referred to. We remove stop words using the standard removeWords transformation like so:
docs <- tm_map(docs, removeWords, stopwords(“english”))
Finally, we remove all extraneous whitespaces using the stripWhitespace transformation:
docs <- tm_map(docs, stripWhitespace)
Stemming
Typically a large corpus will contain many words that have a common root – for example: offer, offered and offering. Stemming is the process of reducing such related words to their common root, which in this case would be the word offer.
Simple stemming algorithms (such as the one in tm) are relatively crude: they work by chopping off the ends of words. This can cause problems: for example, the words mate and mating might be reduced to mat instead of mate. That said, the overall benefit gained from stemming more than makes up for the downside of such special cases.
To see what stemming does, let’s take a look at the last few lines of the corpus before and after stemming. Here’s what the last bit looks like prior to stemming (note that this may differ for you, depending on the ordering of the corpus source files in your directory):
flexibility eye beholder action increase organisational flexibility say redeploying employees likely seen affected move constrains individual flexibility dual meaning characteristic many organizational platitudes excellence synergy andgovernance interesting exercise analyse platitudes expose difference espoused actual meanings sign wishing many hours platitude deconstructing fun
Now let’s stem the corpus and reinspect it.
writeLines(as.character(docs[[30]]))
flexibl eye behold action increas organis flexibl say redeploy employe like seen affect move constrain individu flexibl dual mean characterist mani organiz platitud excel synergi andgovern interest exercis analys platitud expos differ espous actual mean sign wish mani hour platitud deconstruct fun
A careful comparison of the two paragraphs reveals the benefits and tradeoff of this relatively crude process.
There is a more sophisticated procedure called lemmatization that takes grammatical context into account. Among other things, determining the lemma of a word requires a knowledge of its part of speech (POS) – i.e. whether it is a noun, adjective etc. There are POS taggers that automate the process of tagging terms with their parts of speech. Although POS taggers are available for R (see this one, for example), I will not go into this topic here as it would make a long post even longer.
On another important note, the output of the corpus also shows up a problem or two. First, organiz and organis are actually variants of the same stem organ. Clearly, they should be merged. Second, the word andgovern should be separated out into and and govern (this is an error in the original text). These (and other errors of their ilk) can and should be fixed up before proceeding. This is easily done using gsub() wrapped in content_transformer. Here is the code to clean up these and a few other issues that I found:
Note that I have removed the stop words and and in in the 3rd and 4th transforms above.
There are definitely other errors that need to be cleaned up, but I’ll leave these for you to detect and remove.
The document term matrix
The next step in the process is the creation of the document term matrix (DTM)– a matrix that lists all occurrences of words in the corpus, by document. In the DTM, the documents are represented by rows and the terms (or words) by columns. If a word occurs in a particular document, then the matrix entry for corresponding to that row and column is 1, else it is 0 (multiple occurrences within a document are recorded – that is, if a word occurs twice in a document, it is recorded as “2” in the relevant matrix entry).
A simple example might serve to explain the structure of the TDM more clearly. Assume we have a simple corpus consisting of two documents, Doc1 and Doc2, with the following content:
Doc1: bananas are yellow
Doc2: bananas are good
The DTM for this corpus would look like:
| bananas | are | yellow | good | |
| Doc1 | 1 | 1 | 1 | 0 |
| Doc2 | 1 | 1 | 0 | 1 |
Clearly there is nothing special about rows and columns – we could just as easily transpose them. If we did so, we’d get a term document matrix (TDM) in which the terms are rows and documents columns. One can work with either a DTM or TDM. I’ll use the DTM in what follows.
There are a couple of general points worth making before we proceed. Firstly, DTMs (or TDMs) can be huge – the dimension of the matrix would be number of document x the number of words in the corpus. Secondly, it is clear that the large majority of words will appear only in a few documents. As a result a DTM is invariably sparse – that is, a large number of its entries are 0.
The business of creating a DTM (or TDM) in R is as simple as:
This creates a term document matrix from the corpus and stores the result in the variable dtm. One can get summary information on the matrix by typing the variable name in the console and hitting return:
<<DocumentTermMatrix (documents: 30, terms: 4209)>>
Non-/sparse entries: 14252/112018
Sparsity : 89%
Maximal term length: 48
Weighting : term frequency (tf)
This is a 30 x 4209 dimension matrix in which 89% of the rows are zero.
One can inspect the DTM, and you might want to do so for fun. However, it isn’t particularly illuminating because of the sheer volume of information that will flash up on the console. To limit the information displayed, one can inspect a small section of it like so:
<<DocumentTermMatrix (documents: 2, terms: 6)>>
Non-/sparse entries: 0/12
Sparsity : 100%
Maximal term length: 8
Weighting : term frequency (tf)
Docs creation creativ credibl credit crimin crinkl
BeyondEntitiesAndRelationships.txt 0 0 0 0 0 0
bigdata.txt 0 0 0 0 0 0
This command displays terms 1000 through 1005 in the first two rows of the DTM. Note that your results may differ.
Mining the corpus
Notice that in constructing the TDM, we have converted a corpus of text into a mathematical object that can be analysed using quantitative techniques of matrix algebra. It should be no surprise, therefore, that the TDM (or DTM) is the starting point for quantitative text analysis.
For example, to get the frequency of occurrence of each word in the corpus, we simply sum over all rows to give column sums:
Here we have first converted the TDM into a mathematical matrix using the as.matrix() function. We have then summed over all rows to give us the totals for each column (term). The result is stored in the (column matrix) variable freq.
Check that the dimension of freq equals the number of terms:
length(freq)
[1] 4209
Next, we sort freq in descending order of term count:
ord <- order(freq,decreasing=TRUE)
Then list the most and least frequently occurring terms:
freq[head(ord)]
one organ can manag work system
314 268 244 222 202 193
#inspect least frequently occurring terms
freq[tail(ord)]
yield yorkshir youtub zeno zero zulli
1 1 1 1 1 1
The least frequent terms can be more interesting than one might think. This is because terms that occur rarely are likely to be more descriptive of specific documents. Indeed, I can recall the posts in which I have referred to Yorkshire, Zeno’s Paradox and Mr. Lou Zulli without having to go back to the corpus, but I’d have a hard time enumerating the posts in which I’ve used the word system.
There are at least a couple of ways to simple ways to strike a balance between frequency and specificity. One way is to use so-called inverse document frequencies. A simpler approach is to eliminate words that occur in a large fraction of corpus documents. The latter addresses another issue that is evident in the above. We deal with this now.
Words like “can” and “one” give us no information about the subject matter of the documents in which they occur. They can therefore be eliminated without loss. Indeed, they ought to have been eliminated by the stopword removal we did earlier. However, since such words occur very frequently – virtually in all documents – we can remove them by enforcing bounds when creating the DTM, like so:
bounds = list(global = c(3,27))))
Here we have told R to include only those words that occur in 3 to 27 documents. We have also enforced lower and upper limit to length of the words included (between 4 and 20 characters).
Inspecting the new DTM:
<<DocumentTermMatrix (documents: 30, terms: 1290)>>
Non-/sparse entries: 10002/28698
Sparsity : 74%
Maximal term length: 15
Weighting : term frequency (tf)
The dimension is reduced to 30 x 1290.
Let’s calculate the cumulative frequencies of words across documents and sort as before:
#length should be total number of terms
length(freqr)
[1] 1290
#create sort order (asc)
ordr <- order(freqr,decreasing=TRUE)
#inspect most frequently occurring terms
freqr[head(ordr)]
organ manag work system project problem
268 222 202 193 184 171
#inspect least frequently occurring terms
freqr[tail(ordr)]
wait warehous welcom whiteboard wider widespread
3 3 3 3 3 3
The results make sense: the top 6 keywords are pretty good descriptors of what my blogs is about – projects, management and systems. However, not all high frequency words need be significant. What they do, is give you an idea of potential classification terms.
That done, let’s take get a list of terms that occur at least a 100 times in the entire corpus. This is easily done using the findFreqTerms() function as follows:
[1] “action” “approach” “base” “busi” “chang” “consult” “data” “decis” “design”
[10] “develop” “differ” “discuss” “enterpris” “exampl” “group” “howev” “import” “issu”
[19] “like” “make” “manag” “mani” “model” “often” “organ” “peopl” “point”
[28] “practic” “problem” “process” “project” “question” “said” “system” “thing” “think”
[37] “time” “understand” “view” “well” “will” “work”
Here I have asked findFreqTerms() to return all terms that occur more than 80 times in the entire corpus. Note, however, that the result is ordered alphabetically, not by frequency.
Now that we have the most frequently occurring terms in hand, we can check for correlations between some of these and other terms that occur in the corpus. In this context, correlation is a quantitative measure of the co-occurrence of words in multiple documents.
The tm package provides the findAssocs() function to do this. One needs to specify the DTM, the term of interest and the correlation limit. The latter is a number between 0 and 1 that serves as a lower bound for the strength of correlation between the search and result terms. For example, if the correlation limit is 1, findAssocs() will return only those words that always co-occur with the search term. A correlation limit of 0.5 will return terms that have a search term co-occurrence of at least 50% and so on.
Here are the results of running findAssocs() on some of the frequently occurring terms (system, project, organis) at a correlation of 60%.
project
inher 0.82
handl 0.68
manag 0.68
occurr 0.68
manager’ 0.66
enterpris
agil 0.80
realist 0.78
increment 0.77
upfront 0.77
technolog 0.70
neither 0.69
solv 0.69
adapt 0.67
architectur 0.67
happi 0.67
movement 0.67
architect 0.66
chanc 0.65
fine 0.64
featur 0.63
system
design 0.78
subset 0.78
adopt 0.77
user 0.77
involv 0.71
specifi 0.71
function 0.70
intend 0.67
softwar 0.67
step 0.67
compos 0.66
intent 0.66
specif 0.66
depart 0.65
phone 0.63
frequent 0.62
today 0.62
pattern 0.61
cognit 0.60
wherea 0.60
An important point to note that the presence of a term in these list is not indicative of its frequency. Rather it is a measure of the frequency with which the two (search and result term) co-occur (or show up together) in documents across . Note also, that it is not an indicator of nearness or contiguity. Indeed, it cannot be because the document term matrix does not store any information on proximity of terms, it is simply a “bag of words.”
That said, one can already see that the correlations throw up interesting combinations – for example, project and manag, or enterpris and agil or architect/architecture, or system and design or adopt. These give one further insights into potential classifications.
As it turned out, the very basic techniques listed above were enough for me to get a handle on the original problem that led me to text mining – the analysis of free text problem descriptions in my organisation’s service management tool. What I did was to work my way through the top 50 terms and find their associations. These revealed a number of sets of keywords that occurred in multiple problem descriptions, which was good enough for me to define some useful sub-categories. These are currently being reviewed by the service management team. While they’re busy with that that, I’m looking into refining these further using techniques such as cluster analysis and tokenization. A simple case of the latter would be to look at two-word combinations in the text (technically referred to as bigrams). As one might imagine, the dimensionality of the DTM will quickly get out of hand as one considers larger multi-word combinations.
Anyway, all that and more will topics have to wait for future articles as this piece is much too long already. That said, there is one thing I absolutely must touch upon before signing off. Do stay, I think you’ll find it interesting.
Basic graphics
One of the really cool things about R is its graphing capability. I’ll do just a couple of simple examples to give you a flavour of its power and cool factor. There are lots of nice examples on the Web that you can try out for yourself.
Let’s first do a simple frequency histogram. I’ll use the ggplot2 package, written by Hadley Wickham to do this. Here’s the code:
library(ggplot2)
p <- ggplot(subset(wf, freqr>100), aes(term, occurrences))
p <- p + geom_bar(stat=”identity”)
p <- p + theme(axis.text.x=element_text(angle=45, hjust=1))
p
Figure 1 shows the result.

Fig 1: Term-occurrence histogram (freq>100)
The first line creates a data frame – a list of columns of equal length. A data frame also contains the name of the columns – in this case these are term and occurrence respectively. We then invoke ggplot(), telling it to consider plot only those terms that occur more than 100 times. The aes option in ggplot describes plot aesthetics – in this case, we use it to specify the x and y axis labels. The stat=”identity” option in geom_bar () ensures that the height of each bar is proportional to the data value that is mapped to the y-axis (i.e occurrences). The last line specifies that the x-axis labels should be at a 45 degree angle and should be horizontally justified (see what happens if you leave this out). Check out the voluminous ggplot documentation for more or better yet, this quick introduction to ggplot2 by Edwin Chen.
Finally, let’s create a wordcloud for no other reason than everyone who can seems to be doing it. The code for this is:
library(wordcloud)
#setting the same seed each time ensures consistent look across clouds
set.seed(42)
#limit words by specifying min frequency
wordcloud(names(freqr),freqr, min.freq=70)
The result is shown Figure 2.

Fig 2: Wordcloud (freq>70)
Here we first load the wordcloud package which is not loaded by default. Setting a seed number ensures that you get the same look each time (try running it without setting a seed). The arguments of the wordcloud() function are straightforward enough. Note that one can specify the maximum number of words to be included instead of the minimum frequency (as I have done above). See the word cloud documentation for more.
This word cloud also makes it clear that stop word removal has not done its job well, there are a number of words it has missed (also and however, for example). These can be removed by augmenting the built-in stop word list with a custom one. This is left as an exercise for the reader :-).
Finally, one can make the wordcloud more visually appealing by adding colour as follows:
wordcloud(names(freqr),freqr,min.freq=70,colors=brewer.pal(6,”Dark2″))
The result is shown Figure 3.

Fig 3: Wordcloud (freq > 70)
You may need to load the RColorBrewer package to get this to work. Check out the brewer documentation to experiment with more colouring options.
Wrapping up
This brings me to the end of this rather long (but I hope, comprehensible) introduction to text mining R. It should be clear that despite the length of the article, I’ve covered only the most rudimentary basics. Nevertheless, I hope I’ve succeeded in conveying a sense of the possibilities in the vast and rapidly-expanding discipline of text analytics.
Note added on July 22nd, 2015:
If you liked this piece, you may want to check out the sequel – a gentle introduction to cluster analysis using R.
Note added on September 29th 2015:
…and my introductory piece on topic modeling.
Note added on December 3rd 2015:
…and my article on visualizing relationships between documents.



{kind=link}