Monte Carlo simulation of multiple project tasks – three examples and some general comments
Introduction
In my previous post I demonstrated the use of a Monte Carlo technique in simulating a single project task with completion times described by a triangular distribution. My aim in that article was to: a) describe a Monte Carlo simulation procedure in enough detail for someone interested to be able to reproduce the calculations and b) show that it gives sensible results in a situation where the answer is known. Now it’s time to take things further. In this post, I present simulations for two tasks chained together in various ways. We shall see that, even with this small increase in complexity (from one task to two), the results obtained can be surprising. Specifically, small changes in inter-task dependencies can have a huge effect on the overall (two-task) completion time distribution. Although, this is something that that most project managers have experienced in real life, it is rarely taken in to account by traditional scheduling techniques. As we shall see, Monte Carlo techniques predict such effects as a matter of course.
Background
The three simulations discussed here are built on the example that I used in my previous article, so it’s worth spending a few lines for a brief recap of that example. The task simulated in the example was assumed to be described by a triangular distribution with minimum completion time (


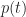

Figure 1 - PDF for triangular distribution (tmin=2, tml=4, tmax=8)
Figure 2 depicts the associated cumulative distribution function (CDF), 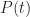

Figure 2 - PDF for triangular distribution (tmin=2, tml=4, tmax=6)
The equations describing the PDF and CDF are listed in equations 4-7 of my previous article. I won’t rehash them here as they don’t add anything new to the discussion – please see the article for all the gory algebraic details and formulas. Now, with that background, we’re ready to move on to the examples.
Two tasks in series with no inter-task delay
As a first example, let’s look at two tasks that have to be performed sequentially – i.e. the second task starts as soon as the first one is completed. To simplify things, we’ll also assume that they have identical (triangular) distributions as described earlier and shown in Figure 1 (excepting , of course, that the distribution is shifted to the right for the second task – since it starts after the first one finishes). We’ll also assume that the second task begins right after the first one is completed (no inter-task delay) – yes, this is unrealistic, but bear with me. The simulation algorithm for the combined tasks is very similar to the one for a single task (described in detail in my previous post). Here’s the procedure:
- For each of the two tasks, generate a set of N random numbers. Each random number generated corresponds to the cumulative probability of completion for a single task on that particular run.
- For each random number generated, find the time corresponding to the cumulative probability by solving equation 6 or 7 in my previous post.
- Step 2 gives N sets of completion times. Each set has two completion times – one for each tasks.
- Add up the two numbers in each set to yield the comple. The resulting set corresponds to N simulation runs for the combined task.
I then divided the time interval from t=4 hours (min possible completion time for both tasks) to t=16 hours (max possible completion time for both tasks) into bins of 0.25 hrs each, and then assigned each combined completion time to the appropriate bin. For example, if the predicted completion time for a particular run was 9.806532 hrs, it was assigned to the bin corresponding to 0.975 hrs. The resulting histogram is shown in Figure 3 below (click on image to view the full-size graphic).

Figure 3 - Frequency histogram for tasks in series with no inter-task delay
[An aside: compare the histogram in Figure 3 to the one for a single task (Figure 1): the distribution for the single task is distinctly asymmetric (the peak is not at the centre of the distribution) whereas the two task histogram is nearly symmetric. This surprising result is a consequence of the Central Limit Theorem (CLT) – which states that the sum of many identical distributions tends to resemble the Normal (Bell-shaped) distribution, regardless of the shape of the individual distributions. Note that the CLT holds even though the two task distributions are shifted relative to each other – i.e. the second task begins after the first one is completed.]
The simulation also enables us to compute the cumulative probability of completion for the combined tasks (the CDF). This value of the cumulative probability at a particular bin equals the sum of the number of simulations runs in every bin up to (and including) the bin in question, divided by the total number of simulation runs. In mathematical terms this is:
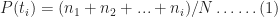
where 
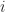


The resulting cumulative probability function is shown in Figure 4. This allows us to answer questions such as: “What is the probability that the tasks will be completed within 10 days?”. Answer: .698, or approximately 70%. (Note: I obtained this number by interpolating between values obtained from equation (1), but this level of precision is uncalled for, particularly because the formula is an approximate one)

Figure 4 - CDF for tasks in series with no inter-task delay
Many project scheduling techniques compute average completion times for component tasks and then add them up to get the expected completion time for the combined task. In the present case the average works out to 9.33 hrs (twice the average for a single task). However, we see from the CDF that there is a significant probability (.43) that we will not finish by this time – and this in a “best-case ” situation where the second task starts immediately after the first one finishes!
[An aside: If one applies the well-known PERT formula 
As interesting as this case is, it is somewhat unrealistic because successor tasks seldom start the instant the predecessor is completed. More often than not, there is a cut-off time before which the successor cannot start – even if there are no explicit dependencies between the two tasks. This observation is a perfect segue into my next example, which is…
Two tasks in series with a fixed earliest start for the successor
Now we’ll introduce a slight complication: let’s assume, as before, that the two tasks are done one after the other but that the earliest the second task can start is at 
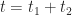

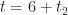
I divided the time interval from t=4hrs to t=20 hrs into bins of 0.25 hr duration (much as I did before) and then assigned each combined completion time to the appropriate bin. The resulting histogram is shown in Figure 5.

Figure 5 - Frequency histogram for tasks in series with inter-task delay
Comparing Figure 5 to Figure 3, we see that the earliest possible finish time now increases from 4 hrs to 8 hrs. This is no surprise, as we built this in to our assumption. Further, as one might expect, the distribution is distinctly asymmetric – with a minimum completion time of 8 hrs, a most likely time between 10 and 11 hrs and a maximum completion time of about 15 hrs.
Figure 6 shows the cumulative probability of completion for this case.

Figure 6 - CDF for tasks in series with inter-task delay
Because of the delay condition, it is impossible to calculate the average completion from the formulas for the triangular distribution – we have to obtain it from the simulation. The average can be calculated from the simulation adding up all completion times and dividing by the total number of simulations,

where 
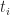
This procedure gave me a value of about 10.8 hrs for the average. From the CDF in Figure 6 one sees that the probability that the combined task will finish by this time is only 0.60 – i.e. there’s only a 60% chance that the task will finish by this time. Any naïve estimation of time would do just as badly unless, of course, one is overly pessimistic and assumes a completion time of 15 – 16 hrs.
From the above it should be evident that the simulation allows one to associate an uncertainty (or probability) with every estimate. If management imposes a time limit of 10 hours, the project manager can refer to the CDF in Figure 6 and figure out the probability of completing the task by that time (there’s a 40 % chance of completion by 10 hrs). Of course, the reliability of the numbers depend on how good the distribution is. But the assumptions that have gone into the model are known – the optimistic, most likely and pessimistic times and the form of the distribution – and these can be refined as one gains experience.
Two tasks in parallel
My final example is the case of two identical tasks performed in parallel. As above, I’ll assume the uncertainty in each task is characterized by a triangular distribution with 
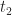
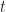

To plot the histogram shown in Figure 7 , I divided the interval from t=2 hrs to t=8 hrs into bins of 0.25 hr duration each (Warning: Note the difference in the time axis scale from Figures 3 and 5!).

Figure 7 - Frequency histogram for tasks in parallel
It is interesting to compare the above histogram with that for an individual task with the same parameters (i.e. the example that was used in my previous post). Figure 8 shows the histograms for the two examples on the same plot (the combined task in red and the single task in blue). As one might expect, the histogram for the combined task is shifted to the right, a consequence of the nonlinear condition on the completion time.

Figure 8 - Histograms for tasks in parallel (red) and single task (blue)
What about the average? I calculated the average as before, by using equation (2) from the previous section. This gives an average of 5.38 hrs (compared to 4.67 hrs for either task, taken individually). Note that the method to calculate the average is the same regardless of the form of the distribution. On the other hand, computing the average from the equations would be a complicated affair, involving a stiff dose of algebra with an optional sprinkling of calculus. Even worse – the calculations would vary from distribution to distribution. There’s no question that simulations are much easier.
The CDF for the overall completion time is also computed easily using equation (1). The resulting plot is shown in Figure 9 (Note the difference in the time axis scale from Figures 4 and 6!). There are no surprises here – excepting how easy it is to calculate once the simulation is done.

Figure 9 - CDF for tasks in parallel
Let’s see what time corresponds to a 90% certainty of completion. A rough estimate for this number can be obtained from Figure 9 – just find the value of t (on the x axis) corresponding to a cumulative probability of 0.9 (on the y axis). This is the graphical equivalent of solving the CDF for time, given the cumulative probability is 0.9. From Figure 9, we get a time of approximately 6.7 hrs. [Note: we could get a more accurate number by fitting the points obtained from equation (1) to a curve and then calculating the time corresponding to 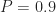
Comparing the two histograms in Figure 8, we expect the biggest differences in cumulative probability to occur at about the t=4 hour mark, because by that time the probability for the individual task has peaked whereas that for the combined task is yet to peak. Let’s see if this is so: from Figure 8, the cumulative probability for t=4 hrs is about .15 and from the CDF for the triangular distribution (equation 6 from my previous post), the cumulative probability at t=4 hours (which is the most likely time) is .333 – double that of the combined task. This, again, isn’t too surprising (once one has Figure 8 on hand). The really nice thing is that we are able to attach uncertainties to all our estimates.
Conclusion
Although the examples discussed above are simple – two identical tasks with uncertainties described by a triangular distribution – they serve to illustrate some of the non-intuitive outcomes when tasks have dependencies. It is also worth noting that although the distribution for the individual tasks is known, the only straightforward way to obtain the distributions for the combined tasks (figures 3, 5 and 7) is through simulations. So, even these simple examples are a good demonstration of the utility of Monte Carlo techniques. Of course, real projects are way more complicated, with diverse tasks distributed in many different ways. To simplify simulations in such cases, one could perform coarse-grained simulations on a small number of high-level tasks, each consisting of a number of low-level, atomic tasks. The high-level tasks could be constructed in such a way as to focus attention on areas of greatest complexity, and hence greatest uncertainty.
As I have mentioned several times in this article and the previous one: simulation results are only as good as the distributions on which they are based. This begs the question: how do we know what’s an appropriate distribution for a given situation? There’s no one-size-fits-all answer to this question. However, for project tasks there are some general considerations that apply. These are:
- There is a minimum time (
- The probability will increase from 0 at
- The probability decreases as time increases beyond
Asymmetric triangular distributions (such as the one used in my examples) are the simplest distributions that satisfy these conditions. Furthermore, a three point estimate is enought to specify a triangular distribution completely – i.e. given a three point estimate there is only one triangular distribution that can be fitted to it. That said, there are several other distributions that can be used; of particular relevance are certain long-tailed distributions.
Finally, I should mention that I make no claims about the efficiency or accuracy of the method presented here: it should be seen as a demonstration rather than a definitive technique. The many commercial Monte Carlo tools available in the market probably offer far more comprehensive, sophisticated and reliable algorithms (Note: I ‘ve never used any of them, so I can’t make any recommendations!). That said, it is always helpful to know the principles behind such tools, if for no other reason than to understand how they work and, more important, how to use them correctly. The material discussed in this and the previous article came out of my efforts to develop an understanding Monte Carlo techniques and how they can be applied to various aspects of project management (they can also be applied to cost estimation, for example). Over the last few weeks I’ve spent many enjoyable evenings developing and running these simulations, and learning from them. I’ll leave it here with the hope that you find my articles helpful in your own explorations of the wonderful world of Monte Carlo simulations.



One ever so slight detail.
The PDF says what the “denisty” of allowable completion times are. The CDF is the probability of completing “on or before.”
The PDF is the sample space used to draw a duration for the tasks for evaluating the network. Triangle is the right PDF in the absence of the underlying population statistics.
Lots is issues with coupling between tasks and what the commerical tools call cruitiality.
LikeLike
Glen B. Alleman
September 21, 2009 at 6:13 am
Another slight detail
The parallel model is “merge bias”
Click to access Hulett_David.pdf
Click to access 193.pdf
LikeLike
Glen B. Alleman
September 21, 2009 at 6:16 am
Glen,
Thanks for your comments and references.
You’re right. The PDF is best thought of as a density function – i.e. the probability that a task will finish in the infinitesmal time interval dt (lying between t and t+dt) is given by p(t)dt, where p is the PDF. I deliberately chose to use the inaccurate definition in the interest of keeping things simple.
I haven’t used any of the commercial tools – I really should take a look; they seem to have a lot to offer.
Regards,
Kailash.
LikeLike
K
September 21, 2009 at 6:38 am
K,
I suspect you can download a trial version of Risk+ – my favorite.
LikeLike
Glen Alleman
September 21, 2009 at 1:17 pm
What level of WBS can Risk+ handle? For example a WBS decomposed to level 6 with literally thousand of nodes? How long does it take? I think I tried Risk+ about 5 years ago and as I recall it took about 2 hours or more for a WBS down to level 4 with perhaps a few hundred nodes I can’t remember the number of iterations? I am going to demo the trial, but first pass has issues with my Window 7 64 bit configuration.
LikeLike
Robert Higgins
September 26, 2009 at 12:23 am
Robert,
We’ve used Risk+ on 10,000 line projects. Risk+ itself works only on the tasks of the schedule.
LikeLike
Glen B. Alleman
September 26, 2009 at 12:29 am
[…] with Monte Carlo Simulation « Cognitive biases as project meta-risks – part 2 Monte Carlo simulation of multiple project tasks – three examples and some general commen… […]
LikeLike
An introduction to Monte Carlo simulation of project tasks « Eight to Late
September 21, 2009 at 6:23 pm
Thanks for walking through the details, and clarifying the math. I have been reading up on this topic and this is a nice perspective on why it is better and simpler to use Monte Carlo.
Cheers
LikeLike
Robert Higgins
September 23, 2009 at 12:38 am
Robert,
Thanks for your appreciative comments.
Note that simulations can get quite complex for real-life projects with several tasks and dependencies. Although commercially available tools (such as the one suggested by Glen) can make life easier, one still needs to model tasks accurately. The results obtained from simulations are only as good as the estimates that have gone into them.
The benefit of Monte Carlo is that it treats estimates as distributions – thus emphasising the uncertainty associated with them.
Regards,
Kailash.
LikeLike
K
September 23, 2009 at 6:44 am
[…] of project tasks: the the first post presented a fairly detailed introduction to the technique and the second illustrated its use via three simple examples. The examples in the latter demonstrated the effect […]
LikeLike
The effect of task duration correlations on project uncertainty – a study using Monte Carlo simulation « Eight to Late
December 11, 2009 at 10:03 am
Hi K,
I have recently started estimating tasks based on MC menthod. I started with PERT and then refined my estimates by using MCS. I was able to do that on Excel for 6 Tasks with no task delay ( 5000 trials )
Now I will be studing your other posts on task delays and parellel task simulations. Let me know what is right size of no. of trials ( iterations ) to see right results ?
LikeLike
Nikhil
April 15, 2010 at 6:21 pm
Nikhil,
In a nutshell: the number of iterations should be determined by the stability of the results.
Here’s how you could determine it in practice. Begin with a relatively small number of iterations and increase them in steps of 1000 trials (as an example). The quantities of interest (90% completion time, average time or whatever) should converge as the number of iterations increases. You have the right number of iterations When you get to a point where the difference between results from subsequent simulations becomes small.
You’ll find several rules of thumb on the Web. See the following article for example:
http://www.vosesoftware.com/ModelRiskHelp/index.htm#Monte_Carlo_simulation/How_many_iterations_to_run.htm
However, these are far from universally applicable. The best approach is to work it out by running a number of simulations with different numbers of trials, as I’ve suggested above.
Hope this helps.
Regards,
Kailash.
LikeLike
K
April 15, 2010 at 9:45 pm
K,
In risk plus we determine the maxim number of numbers by seeking convergence between the mean and the standard deviation from the mean.
Not new information is provided once the STDDEV stops changing from its normalized value – 1.0.
This means another sample set does not statistically move the durations from those in the previous cumulative sample sets.
Risk+ has a graph showing the normalized difference between the Mean and the STDEV has the runs are being executed.
LikeLike
Glen B Alleman
April 17, 2010 at 1:17 am
Thanks Glen,
That makes sense: the simulation can be considered to be stable (converged) when the mean and SD (or any other characteristics of the distribution) do not change significantly as the number of trials is increased further.
In my homegrown examples I check for convergence by tracking how quantities of interest change as the number of trials was increase. The nice thing about commercial products is that they have such checks built in (with nice visuals too!).
Regards,
Kailash.
LikeLike
K
April 17, 2010 at 8:06 am
Hi K,
another q ?
on the excel sheet, after I complete the simulation calc, I prepare 3 coloums for preparing a Histogram.
Bins,frequency and Cummumaltive frequency.
I see that the cummulative probability increases as the time increases beyond T(ml). This is contrary to your third assumption mentioned above. However, the frequency of no. of times each time ( separated by .25 hrs )decreases in the data array of time values calculated using equation 7 of your introductory article.
LikeLike
Nikhil
April 15, 2010 at 6:33 pm
Nikhil,
My third assumption states that the probability decreases beyond t_ml. This is correct: t_ml, by definition, is the maximum of the probability density function (which is shown in Fig 1). The cumulative probability, on the hand, is given by the sum (or technically, the integral) of the probability density function: it therefore goes from 0 to 1 as a strictly increasing function of time, as shown in Figs. 4, 6 and 9.
Hope this answers your question. Don’t hesitate to let me know if you have any further queries.
Regards,
Kailash.
LikeLike
K
April 15, 2010 at 9:52 pm
hi K,
I have another observation. In real time business situaton, fixed earliest start start for the successor task is seldom seen.
In a situation, where task delay cannot be determined as it depends on so many factors meaning that sometimes 2nd task cannot start because of some delay or the other, can we also simulate task delay based on the same technique as we did for time estimation and then calculate total time for combined task. if yes, how ?
LikeLike
Nikhil
April 15, 2010 at 11:00 pm
Nikhil,
Responses to your queries:
1. A common situation where a fixed start occurs for a successor task is when a resource is not available until a specified time.
2. Task delays can be simulated in exactly the same way as task durations are: they are, after all, just uncertain time intervals. The key, of course, is to determine what the correct distribution is. This – as I have mentioned in my posts – is far from straightforward.
Hope this helps.
Regards,
Kailash.
LikeLike
K
April 16, 2010 at 9:32 pm
Hi K,
Thanks for clarifying CDF function. Now it is much more clear.
Regards
Nikhil
LikeLike
Nikhil
April 15, 2010 at 11:19 pm
Hi K,
Thanks for your time and effort in answering my q’s.
In the section, where you have mentioned that if the task finishes before 6 hrs, there will be a delay in completion of the 1st task and start of the 2nd. I could not understand that. If the 1st tasks finishes within 6 hrs, i might as well start the 2nd task immediately..why wait ? Therefore, adding 6 to task 2 and calculating total time would delay the total time further. pls. correct me if I am wrong.
why do we have to assume fixed earliest start for the 2nd task?
Regards
Nikhil
LikeLike
Nikhil
April 16, 2010 at 7:17 pm
See the first point in my response above for an example of a situation where a fixed start can occur.
K.
LikeLike
K
April 16, 2010 at 9:34 pm
[…] of the fact that probabilities cannot be “added up” like simple numbers. See the first example in my post on Monte Carlo simulation of project tasks for an illustration of this […]
LikeLike
The Flaw of Averages – a book review « Eight to Late
May 4, 2010 at 11:06 pm
[…] In earlier posts, I discussed how these methods can be used to simulate project task durations (see this post and this one for example). In those articles, I described simulation procedures in enough detail […]
LikeLike
The drunkard’s dartboard: an intuitive explanation of Monte Carlo methods | Eight to Late
February 25, 2011 at 4:58 am