Monte Carlo simulation of risk and uncertainty in project tasks
Introduction
When developing duration estimates for a project task, it is useful to make a distinction between the uncertainty inherent in the task and uncertainty due to known risks. The former is uncertainty due to factors that are not known whereas the latter corresponds uncertainty due to events that are known, but may or may not occur. In this post, I illustrate how the two types of uncertainty can be combined via Monte Carlo simulation. Readers may find it helpful to keep my introduction to Monte Carlo simulations of project tasks handy, as I refer to it extensively in the present piece.
Setting the stage
Let’s assume that there’s a task that needs doing, and the person who is going to do it reckons it will take between 2 and 8 hours to complete it, with a most likely completion time of 4 hours. How the estimator comes up with these numbers isn’t important here – maybe there’s some guesswork, maybe some padding or maybe it is really based on experience (as it should be). For simplicity we’ll assume the probability distribution for the task duration is triangular. It is not hard to show that, given the above mentioned estimates, the probability, 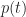
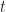
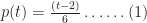

And,
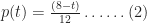
These two expressions are sometimes referred to as the probability distribution function (PDF). The PDF described by equations (1) and (2) is illustrated in Figure 1. (Note: Please click on the Figures to view full-size images)

Figure 1: Probability distribution for task
Now, a PDF tells us the probability that the task will finish at a particular time 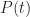
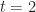

and,

For a detailed derivation, please see my introductory post. The CDF for the distribution is shown in Figure 2.

Figure 2: CDF for task
Now for the complicating factor: let us assume there is a risk that has a bearing on this task. The risk could be any known factor that has a negative impact on task duration. For example, it could be that a required resource is delayed or that the deliverable will fails a quality check and needs rework. The consequence of the risk – should it eventuate – is that the task takes longer. How much longer the task takes depends on specifics of the risk. For the purpose of this example we’ll assume that the additional time taken is also described by a triangular distribution with a minimum, most likely and maximum time of 1, 2 and 3 hrs respectively. The PDF 

And

The figure for this distribution is shown in Figure 3.

Figure 3: Probability distribution of additional time due to risk
The CDF for the additional time taken if the risk eventuates (which we’ll denote by 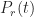

and,
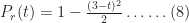
The CDF for the risk consequence is shown in Figure 4.

Figure 4: CDF of additional time due to risk
Before proceeding with the simulation it is worth clarifying what all this means, and what we want to do with it.
Firstly, equations 1-4 describe the inherent uncertainty associated with the task while equations 5 through 8 describe the consequences of the risk, if it eventuates.
Secondly, we have described the task and the risk separately. In reality, we need a unified description of the two – a combined distribution function for the uncertainty associated with the task and the risk taken together. This is what the simulation will give us.
Finally, one thing I have not yet specified is the probabilty that the risk will actually occur. Clearly, the higher the probability, the greater the potential delay. Below I carry out simulations for risk probabilities of varying from 0.1 to 0.5.
That completes the specification of the problem – let’s move on to the simulation.
The simulation
The simulation procedure I used for the zero-risk case (i.e. the task described by equations 1 and 2 ) is as follows :
- Generate a random number between 0 and 1. Treat this number as the cumulative probability,
- Find the time,
- Repeat steps (1) and (2) for a sufficiently large number of trials.
The frequency distribution of completion times for the task, based on 30,000 trials is shown in Figure 5.

Figure 5: Simulation histogram for zero-risk case
As we might expect, Figure 5 can be translated to the probability distribution shown in Figure 1 by a straightforward normalization – i.e. by dividing each bar by the total number of trials.
What remains to be done is to incorporate the risk (as modeled in equations 5-6) into the simulation. To simulate the task with the risk, we simply do the following for each trial:
- Simulate the task without the risk as described earlier.
- Generate another random number between 0 and 1.
- If the random number is less than the probability of the risk, then simulate the risk. Note that since the risk is described by a triangular function, the procedure to simulate it is the same as that for the task (albeit with different parameters).
- If the random number is greater than the probability of the risk, do nothing.
- Add the results of 1 and 4. This is the outcome of the trial.
- Repeat steps 1-5 for as many trials as required.
I performed simulations for the task with risk probabilities of 10%, 30% and 50%. The frequency distributions of completion times for these are displayed in Figures 6-8 (in increasing order of probability). As one would expect, the spread of times increases with increasing probability. Further, the distribution takes on a distinct second peak as the probability increases: the first peak is at 


Figure 6: Simulation histogram (10% probability of risk)

Figure 7: Simulation histogram (30% probability of risk)

Figure 8: Frequency histogram (50% probability of risk)
It is also instructive to compare average completion times for the four cases (zero-risk and 10%, 30% and 50%). The average can computed from the simulation by simply adding up the simulated completion times (for all trials) and dividing by the total number of simulation trials (30,000 in our case). On doing this, I get the following:
Average completion time for zero-risk case = 4.66 hr
Average completion time with 10% probability of risk = 4.89 hrs
Average completion time with 30% probability of risk = 5.36 hrs
Average completion time with 50% probability of risk= 5.83 hrs
No surprises here.
One point to note is that the result obtained from the simulation for the zero-risk case compares well with the exact formula for a triangular distribution (see the Wikipedia article for the triangular distribution):

This serves as a sanity check on the simulation procedure.
It is also interesting to compare the cumulative probabilities of completion in the zero-risk and high risk (50% probability) case. The CDFs for the two are shown in Figure 9. The co-plotted CDFs allow for a quick comparison of completion time predictions. For example, in the zero-risk case, there is about a 90% chance that the task will be completed in a little over 6 hrs whereas when the probability of the risk is 50%, the 90% completion time increases to 8 hrs (see Figure 9).

Figure 9: CDFs for zero risk and 50% probability of risk cases
Next steps and wrap up
For those who want to learn more about simulating project uncertainty and risk, I can recommend the UK MOD paper – Three Point Estimates And Quantitative Risk Analysis A Process Guide For Risk Practitioners. The paper provides useful advice on how three point estimates for project variables should be constructed. It also has a good discussion of risk and how it should be combined with the inherent uncertainty associated with a variable. Indeed, the example I have described above was inspired by the paper’s discussion of uncertainty and risk.
Of course, as with any quantitative predictions of project variables, the numbers are only as reliable as the assumptions that go into them, the main assumption here being the three point estimates that were used to derive the distributions for the task uncertainty and risk (equations 1-2 and 5-6). Typically these are obtained from historical data. However, there are well known problems associated with history-based estimates. For one, as we can never be sure that the historical tasks are similar to the one at hand in ways that matter (this is the reference class problem). As Shim Marom warns us in this post, all our predictions depend on the credibility of our estimates. Quoting from his post:
Can you get credible three point estimates? Do you have access to credible historical data to support that? Do you have access to Subject Matter Experts (SMEs) who can assist in getting these credible estimates?
If not, don’t bother using Monte Carlo.
In closing, I hope my readers will find this simple example useful in understanding how uncertainty and risk can be accounted for using Monte Carlo simulations. In the end, though, one should always keep in mind that the use of sophisticated techniques does not magically render one immune to the GIGO principle.



I ❤ Monte Carlo Simulations.
It's funny that IT is fraught with projects and estimates that have tons of risks but even in many insurance companies they don't do proper risk analysis (which is what insurance is all about).
Good example of when you might use Monte Carlo and dealing with uncertainty and risks. 🙂
LikeLike
Richard Harbridge
February 18, 2011 at 6:42 am
Richard,
Thanks for the comment.
Agreed – those who need it the most seem to use it the least. On a related note, I’m reading an interesting paper that challenges the tenets of Enterprise Risk Management. I’ll probably do a summary of it in the near future.
Regards,
K.
LikeLike
K
February 18, 2011 at 7:33 am
[…] to Late Skip to content HomeAuthor ← Monte Carlo simulation of risk and uncertainty in project tasks February 25, 2011 · 4:51 am ↓ Jump to […]
LikeLike
The drunkard’s dartboard: an intuitive explanation of Monte Carlo methods | Eight to Late
February 25, 2011 at 4:51 am
[…] was an in-depth post recently on the Eight to Late project management blog called “Monte Carlo simulation of risk and uncertainty in project tasks” that explained a method to account for both known and unknown risks. The post was enjoyable […]
LikeLike
Project Management: Can I See Your Quantifications? | Ted Simpson
March 9, 2011 at 10:50 pm
[…] estimates; indeed there are a good number of articles on this blog – see this post or this one, for example. However, most of these writings focus on the practical applications of probability […]
LikeLike
The shape of things to come: an essay on probability in project estimation « Eight to Late
April 3, 2012 at 11:40 pm