On the accuracy of group estimates
Introduction
The essential idea behind group estimation is that an estimate made by a group is likely to be more accurate than one made by an individual in the group. This notion is the basis for the Delphi method and its variants. In this post, I use arguments involving probabilities to gain some insight into the conditions under which group estimates are more accurate than individual ones.
An insight from conditional probability
Let’s begin with a simple group estimation scenario.
Assume we have two individuals of similar skill who have been asked to provide independent estimates of some quantity, say a project task duration. Further, let us assume that each individual has a probability 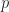
Based on the above, the probability that they both make a correct estimate, 
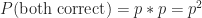
This is a consequence of our assumption that the individual estimates are independent of each other.
Similarly, the probability that they both get it wrong, 

Now we can ask the following question:
What is the probability that both individuals make the correct estimate if we know that they have both made the same estimate?
This can be figured out using Bayes’ Theorem, which in the context of the question can be stated as follows:

In the above equation, 
Similarly, 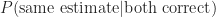
Question: Why?
Answer: If both estimators are correct then they must have made the same estimate (i.e. they must both within be an acceptable range of the right answer).
Finally, 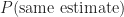
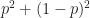
Now lets apply Bayes’ theorem to the following two cases:
- Both individuals are good estimators – i.e. they have a high probability of making a correct estimate. We’ll assume they both have a 90% chance of getting it right (
).
- Both individuals are poor estimators – i.e. they have a low probability of making a correct estimate. We’ll assume they both have a 30% chance of getting it right (
)
Consider the first case. The probability that both estimators get it right given that they make the same estimate is:

Thus we see that the group estimate has a significantly better chance of being right than the individual ones: a probability of 0.9878 as opposed to 0.9.
In the second case, the probability that both get it right is:

The situation is completely reversed: the group estimate has a much smaller chance of being right than an individual estimate!
In summary: estimates provided by a group consisting of individuals of similar ability working independently are more likely to be right (compared to individual estimates) if the group consists of competent estimators and more likely to be wrong (compared to individual estimates) if the group consists of poor estimators.
Assumptions and complications
I have made a number of simplifying assumptions in the above argument. I discuss these below with some commentary.
- The main assumption is that individuals work independently. This assumption is not valid for many situations. For example, project estimates are often made by a group of people working together. Although one can’t work out what will happen in such situations using the arguments of the previous section, it is reasonable to assume that given the right conditions, estimators will use their collective knowledge to work collaboratively. Other things being equal, such collaboration would lead a group of skilled estimators to reinforce each others’ estimates (which are likely to be quite similar) whereas less skilled ones may spend time arguing over their (possibly different and incorrect) guesses. Based on this, it seems reasonable to conjecture that groups consisting of good estimators will tend to make even better estimates than they would individually whereas those consisting of poor estimators have a significant chance of making worse ones.
- Another assumption is that an estimate is either good or bad. In reality there is a range that is neither good nor bad, but may be acceptable.
- Yet another assumption is that an estimator’s ability can be accurately quantified using a single numerical probability. This is fine providing the number actually represents the person’s estimation ability for the situation at hand. However, typically such probabilities are evaluated on the basis of past estimates. The problem is, every situation is unique and history may not be a good guide to the situation at hand. The best way to address this is to involve people with diverse experience in the estimation exercise. This will almost often lead to a significant spread of estimates which may then have to be refined by debate and negotiation.
Real-life estimation situations have a number of other complications. To begin with, the influence that specific individuals have on the estimation process may vary – a manager who is a poor estimator may, by virtue of his position, have a greater influence than others in a group. This will skew the group estimate by a factor that cannot be estimated. Moreover, strategic behaviour may influence estimates in a myriad other ways. Then there is the groupthink factor as well.
…and I’m sure there are many others.
Finally I should mention that group estimates can depend on the details of the estimation process. For example, research suggests that under certain conditions competition can lead to better estimates than cooperation.
Conclusion
In this post I have attempted to make some general inferences regarding the validity of group estimates based on arguments involving conditional probabilities. The arguments suggest that, all other things being equal, a collective estimate from a bunch of skilled estimators will generally be better than their individual estimates whereas an estimate from a group of less skilled estimators will tend to be worse than their individual estimates. Of course, in real life, there are a host of other factors that can come into play: power, politics and biases being just a few. Though these are often hidden, they can influence group estimates in inestimable ways.
Acknowledgement
Thanks go out to George Gkotsis and Craig Brown for their comments which inspired this post.



In light of all the caveats that you wisely apply, do you think the technical result you derive so elegantly actually has any practical implications?
LikeLike
Tim van Gelder
December 1, 2011 at 5:20 pm
Tim,
Thanks for your comment. I agree – in view of the caveats, the practical utility of the model is limited. I offer it in the spirit that simple, idealised models can provide insights into practical situations.
Regards,
Kailash.
LikeLike
K
December 4, 2011 at 2:09 pm
Dear Kailash,
Once again, thank you for your post 🙂 Through probabilities and “formal mathematics” your post demonstrates that there are cases where “collective wisdom” may fail to be wise enough, compared to individual opinions. This is exactly what my point on previous comment was.
Concerning Dr. Gelder’s comment above, I believe that this post manages to quantitatively “prove” how “public opinion” can have a huge difference compared to “public wisdom”. Personally, I find this finding aligned to Gelder’s posts (e.g. http://timvangelder.com/2011/10/14/what-do-we-think-part-1-public-attitude-versus-public-wisdom/), which discusses the various implications of public deliberation and decision making. I would even claim that the one case refers to “reasoning under uncertainty” and wicked problems, where the other refers to routines and traditional decision making, to quote Michael Pidd (Systems Modelling: Theory and Practice, page 17)
Having said the above, there is no doubt that collaboration and group work can increase the quality of knowledge. However, when it comes to assessment, estimations and decisions, an expert’s opinion should be carefully considered, sometimes even promoted over the “tragedy of the commons”.
LikeLike
George Gkotsis
December 1, 2011 at 9:57 pm
George,
Thanks for your comment, in particular the connection you have drawn with Tim’s work on public attitudes vs public wisdom. Although real-life is indeed more complicated than the simple situation I describe, the second case (p=0.3) highlights a potential danger of basing decisions on group attitudes.
Regards,
K.
LikeLike
K
December 4, 2011 at 2:10 pm
[…] via On the accuracy of group estimates « Eight to Late. […]
LikeLike
» On the accuracy of group vs. individual estimates
December 2, 2011 at 5:04 am
Kailash,
For me this is a great insight. I have watched some teams adopt Mike Cohn’s planning poker technique and become wizards and estimating. They are the exception to my general experience.
MOST teams I have worked with were fundamentally not able to estimate with any accuracy, and it seemed the more people we added to the process the more time we were wasting.
In these cases I would dispose of the estimates provided by the group and re-do them with 2 or 3 specialists who clearly had better estimation skills.
I suspect that group estimating a la Cohn’s techniques will only be useful for poor performers if you actively focus on gathering actuals and reflecting on what is going wrong. Maybe that’s useful, maybe not.
LikeLike
Craig Brown
December 3, 2011 at 3:45 pm
Craig,
Thanks for your kind words and the post based on your experience with group estimates.
I agree – developing experience is the key to better estimating. That said one has to be careful because it is all too easy to be mislead by experience: cognitive biases such as anchoring and overconfidence can come into play even when one is an expert. A couple of the things one can do to overcome these biases include: probability calibration and using historical data (which you mention in your post) . When using the latter, one has to be careful to ensure that the historical data is actually relevant to the case at hand. No two situations are identical and one doesn’t know a priori whether the differences are significant or not.
Regards,
K.
PS: The essential mechanism underlying decision-related cognitive biases is the human tendency to base judgements on specific instances that come to mind instead of the range of all possible instances. This mechanism is called attribute substitution. I wrote a post on this some time ago and it is also discussed in detail in our forthcoming book.
LikeLike
K
December 4, 2011 at 2:11 pm
Here is a related topic where the blogger/statistician considers experts v punters in the sports world.
It prompts the question; what enables/makes an expert?
LikeLike
Craig Brown
December 4, 2011 at 10:48 pm
And the link 🙂
http://wmbriggs.com/blog/?p=4817
LikeLike
Craig Brown
December 4, 2011 at 10:49 pm
Thanks Craig, that’s an interesting article indeed. As Briggs mentions in a comment on the article, “What’s interesting is that most people pick around about 65% correctly, both Experts and Users. Experts are better at picking more difficult games, which accounts for the difference.”
I guess the reason experts pick difficult (which I interpret as meaning “close”) games better is that they have a better awareness of relevant factors – i.e. those that differentiate between the teams. I speculate that something similar happens in estimation: good estimators have a better feel for what ought to go into a complex estimate and what can safely be ignored. Perhaps this is where experience and formal training makes a difference?
Regards,
K.
LikeLike
K
December 5, 2011 at 5:39 pm
[…] (“On The Accuracy of Group Estimates“) followed by Craig (“Why You Guys Suck at Estimating“) wrote about the validity […]
LikeLike
My Two Cents About Estimating | quantmleap
December 5, 2011 at 10:39 am
[…] wrote a great blog post on estimating. It gives the maths behind why you guys suck at estimating. Go read the post here. Kailash tells us that essentially your success at estimating is amplified by doing […]
LikeLike
Why you guys suck at estimating | The Agile Radar
December 5, 2011 at 7:01 pm
[…] pre project, but on a story by story there was very little accuracy in estimates. As we know from Kailash's blog post delphi planning (e.g. planning poker) amplifies estimating capability. If your skills are […]
LikeLike
Case Study: Problems with Estimating | The Agile Radar
December 6, 2011 at 7:04 pm
Hope for the poor estimators…
There may be a middle ground where a group of poor estimators can outperform better experts.
As K. points out, the probability that both 90% experts estimate correctly is 81% (90% x 90%)
98% would be “given that both guess the same, are they correct”.
All of the outcomes are: 81% Y/Y : 18% Y/N : 1% N/N)
The implication is that when they differ (18% of the time), they continue estimating until their estimates are the same …and do this independently?
The result of the poor estimators is explained in the same way – 42% of the time, they ‘vote’ and decide on what is most likely – i.e. the wrong answer. (outcomes: 9% Y/Y : 42% Y/N : 49% N/N). Adding more poor estimators to the group would not help at all.
On the other hand, if we accept that the outcome is negotiated, the question is then:
Having made the wrong estimate, how likely is an expert to change their mind when a colleague presents the right estimate?
If the correct estimate “feels” right in the face of other estimates, then your group of previously poor estimators can reverse their fortunes.
Take the scenario of two senior managers (90% estimators, and proud of it). 18% of the time they need to negotiate. In many organisations, this is a good time to go and get a coffee and be away from the office for a while. That leaves them at 81% of arriving at the same correct decision independently. What if they then delegate the decision to their 6 subordinates (30% estimators) who are also very good collaborators? (I’ll propose that critical evaluation, and collaboration skills are independent of the ability to be an expert in one specific area).
The chance of all 6 beginning with the same incorrect estimate is 70%*6 = close to 12%. The rest of the time (88%) at the very least, the right estimate is on the table and is being discussed. The rest is up to their abilities at callaboration etc..
I suspect that the right answer does shine brighter – if the group is flexible enough to look past their own first guesses.
If so, the less skilled subordinates get it right more often.
PS: I’ll concede to a separate point: The benefits of collaboration quickly diminish as group numbers grow … otherwise, we’d all turn up on election day, have a chat and then vote for the same person …. NOT likely!
LikeLike
Sean
December 9, 2011 at 9:57 pm
Sean,
Thanks for a detailed (and entertaining) example that raises some very good points.
I agree that if a group works collaboratively and if the members are open-minded then there is a reasonable chance that they will arrive at a better estimate than any individual would providing the group can distinguish between a good estimate and a bad one. Having the right answer on the table is no guarantee that it will actually be recognised as the right answer. This is especially true if the estimators aren’t particularly competent. For instance, if the group uses a majority opinion as the criterion they will get it wrong more often than they get it right. Using your example to illustrate: if two of the six estimators arrive at the same number, they have only 15% chance of being right (as per my the discussion in the post).
Regards,
K.
LikeLike
K
December 9, 2011 at 10:46 pm
I don’t agree with the premise of this posting. As posed in
the posting, Bayes theorem, as given, does not apply to the situation
described for two reasons: First, Delphi, in it’s purest form,
is not a group discussion or collaboration. In the Delphi
method, each estimator works independently without collaboration. Results are
combined by any number of means: consensus, by vote, or by a autocrat
decision-maker deciding. Groups and teams, on the other hand,
engaged in collaboration to solve a problem or make an
estimate, engage in quite complex and subjective discussion,
some of which is analytic and some of which is subject to any
number of biases most of which are not subject to mathematical
probabilities.
Second, the conjunctive probability of two esitmators (.9 x.9)
does not model a group. It models a business rule that says
both must agree to have an aggreeable outcome. Groups don’t
work that way. One person getting the right answer and convincing the decider is all you need.
To pose a Bayesian situation, three elements are needed: an ‘a
priori’ estimate of an outcome (some say guesstimate); an
independent condition that affects the outcome; and
observations (or forecasts) of the effects of the condition on
the a priori estimate. Given 2 of these 3, we can solve for
the third.
So what do we have here? The independent condition is that
each estimator, call them Tom and Harry, form a team, TH.
Whether they form a team or not is like will it rain or not?
It’s a condition that affects outcome but is an action
entirely driven independently of what happens after the team
is formed. By the way, rain affects mood, and mood affects
decision making, so whether it rains or not could be another
independent condition.
What’s the a priori estimate, E? It’s 0.9, not .81. It’s the
data we have before the condition kicks in. For the decision
maker to be successful, only one estimator needs to be
correct. But we hypothesize that the decision process might be
more successful if Tom and Harry actually work together in
some way in a group (Probability Harry and Tom form a group p
(TH)).
What Bayesians can say is: P(E given TH) is the posterior
improvement on a priori p(E). In equation form
p(E given TH) = P(E = 0.9) * P(TH given E) / P(TH). That is:
the updated posterior knowledge of E given there is a group TH (E given
TH) = a priori knowlege of E (.9) modified by information we
develop about TH. Notice that for the posterior group
performance (E given TH) to be better than the a priori
performance (E =.9), p(TH given E)/p(TH) > 1. That is, if
group’s estimate is only E (no improvement), it is less likely
group really formed and achieved synergy.
Now, like the rain, we should know p(TH). Afterall it’s
independent. If we don’t, we might be able to figure out from
observations: p(TH) = p(TH given E)*P(E) + p(TH given not E)
*p(Not E)
I’ve found that the easiest way to set up and work Bayesian
problems is with a “Bayes Grid”
(http://www.johngoodpasture.com/2010/08/our-friend-bayes-part
-i.html)
LikeLike
John C Goodpasture
January 24, 2012 at 4:20 am
Hi John,
Many thanks for reading the post and taking the time to write a detailed comment. I’ll attempt to address the points you have made in roughly the same order that you have made them. I should also state that I’m not an expert in estimation so please feel free to correct my line of thinking.
First, my key assumption is that the estimates are made independently, so it does apply to at least some variants of the Delphi method (perhaps the pure form that you mention in your comment). However, as I have noted, the assumption of independence may well be invalid in many situations.
Second, my group consists of two estimators who make estimates independently. Therefore, the conjunctive probability (insofar as the model is concerned) is indeed given by the product of their individual estimates.
As you have stated in your excellent post, one needs two events in order to use Bayes Theorem: an independent event and an event that has (or is hypothesised to have) a dependency on the first event. In the case above, the first is the event that both estimators concur and the second is the event that they are both correct (or incorrect). The dependency in this case is not hypothesised, it is a fact – if they are both correct (or incorrect) they must concur. In effect this is a degenerate case of Bayes Theorem; one where the dependency is known.
Finally, I reiterate that my model is simplistic and have noted several caveats to this effect in my post.
Many thanks again for taking the time to read and comment.
Regards,
Kailash.
LikeLike
K
January 24, 2012 at 8:56 pm
[…] Further, let us assume that each individual has a probability p of making a correct estimate.via On the accuracy of group estimates « Eight to Late.My take on this was laid out in a previous post: Why experts fail: Lack of leadership, time or […]
LikeLike
On the accuracy of group vs. individual estimates - Preben Ormen's Blog
June 25, 2012 at 3:33 am
[…] Think back in your career and I am sure you can find examples of this in your product’s history. A major customer hits a critical issue, despite it being “well known” or even documented, which causes an all-hands-on-deck situation. New feature development grinds to a halt… and we were already behind on new features, because we’re human and we all suck at estimation. […]
LikeLike
Defuse your landmines… before it is too late | Chandland – Like running top on my brain
August 24, 2013 at 12:08 am