An introduction to the critical chain method
Introduction
All project managers have to deal with uncertainty as a part of their daily work. Project schedules, so carefully constructed, are riddled with assumptions and uncertainties – particularly in task durations. Most project management treatises (the PMBOK included) recognise this, and so exhort project managers to include uncertainties in their activity duration estimates. However, the same books have little to say on how these uncertainties should be integrated into the project schedule in a meaningful way. Sure, well-established techniques such as PERT incorporate probabilities into a schedule via an averaged or expected duration, but the final schedule is deterministic – i.e each task is assigned a definite completion date, based on the expected duration. Any float that appears in the schedule is purely a consequence of an activity not being on the critical path. The float, such as it is, is not an allowance for uncertainty.
Since PERT was invented in the 1950s, there have been several other attempts to incorporate uncertainty into project scheduling. Some of these include, Monte Carlo simulation and, more recently, Bayesian Networks. Although these techniques have a more sound basis, they don’t really address the question of how uncertainty is to be managed in a project schedule, where individual tasks are strung together one after another. What’s needed is a simple technique to protect a project schedule from Murphy, Parkinson or any other variations that invariably occur during the execution of individual tasks. In the 1990s, Eliyahu Goldratt proposed just such a technique in his business novel, Critical Chain. This post presents a short, yet comprehensive introduction to Goldratt’s critical chain method .
[An Aside: Before proceeding any further I should mention that Goldratt formulated the critical chain method within the framework of his Theory of Constraints (TOC). I won’t discuss TOC in this article, mainly because of space limitations. Moreover, an understanding of TOC isn’t really needed to understand the critical chain method. For those interested in learning about TOC, the best starting point is Goldratt’s business novel, The Goal.]
I begin with a discussion of some general characteristics of activity or task estimates, highlighting the reason why task estimators tend to pad up their estimates. This is followed by a discussion on why the buffers (or safety) that estimators build into individual activities don’t help – i.e. why projects come in late despite the fact that most people add considerable safety factors on to their activity estimates. This then naturally leads on to the heart of the matter: how buffers should be added in order to protect schedules effectively.
Characteristics of activity duration estimates
(Note: Portions of this section have been published previously in my post on the inherent uncertainty of project task estimates)
Consider an activity that you do regularly – such as getting ready in the morning. You have a pretty good idea how long the activity takes on average. Say, it takes you an hour on average to get ready – from when you get out of bed to when you walk out of your front door. Clearly, on a particular day you could be super-quick and finish in 45 minutes, or even 40 minutes. However, there’s a lower limit to the early finish – you can’t get ready in 0 minutes!. On the other hand, there’s really no upper limit. On a bad day you could take a few hours. Or if you slip in the shower and hurt your back, you mayn’t make it at all.
If we were to plot the probability of activity completion for this example as a function of time, it might look something like I’ve depicted in Figure 1. The distribution starts at a non-zero cutoff (corresponding to the minimum time for the activity); increases to a maximum (corresponding to the most probable time); and then falls off rapidly at first, then with a long, slowly decaying, tail. The mean (or average) of the distribution is located to the right of the maximum because of the long tail. In the example, 

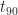
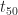

It turns out that many phenomena can be modeled by this kind of long-tailed distribution. Some of the better known long-tailed distributions include lognormal and power law distributions. A quick (but admittedly informal) review of the project management literature revealed that lognormal distributions are more commonly used than power laws to model activity duration uncertainties. This may be because lognormal distributions have a finite mean and variance whereas power law distributions can have infinite values for both (see this presentation by Michael Mitzenmacher, for example). [An Aside:If you’re curious as to why infinities are possible in the latter, it is because power laws decay more slowly than lognormal distributions – i.e they have “fatter” tails, and hence enclose larger (even infinite) areas.]. In any case, regardless of the exact form of the distribution for activity estimates, what’s important and non-controversial is the short cutoff, the peak and long, decaying tail.
Most activity estimators are intuitively aware of the consequences of the long tail. They therefore add a fair amount of “air” or safety in their estimates. Goldratt suggests that typical activity estimates tend to correspond to
Delays accumulate; gains don’t
A schedule is essentially made up of several activities (of varying complexity and duration) connnected sequentially or in parallel. What are the implications of uncertain activity durations on a project schedule? Well, let’s look at the case of sequential and parallel steps separately:
Sequential steps: If an activity finishes early, the successor activity rarely starts right away. More often, the successor activity starts only when it was originally scheduled to. Usually this happens because the resource responsible for the successor activity is not free – or hasn’t been told about the early finish of the predecessor activity. On the other hand, if an activity finishes late, the start of the successor activity is delayed by at least the same amount as the delay. The upshot of all this is that – delays accumulate but early finishes are rarely taken advantage of. So, in a long chain of sequential activities, you can be pretty sure that there will be delays.
Parallel steps: In this case, the longest duration activity dictates the finish time. For example, if we have three parallel activities that take 5 days each. If one of them ends up taking 10 days, the net effect is that three activities, taken together, will complete only after 10 days. In contrast, an early finish will not have an effect unless all activities finish early (and by the same amount!). Again we see that delays accumulate; early finishes don’t.
The above discussion assumed that activities are independent. In a real project activities can be highly dependent. In general this tends to make things worse – a delay in an activity is usually magnified by a dependent successor activity.
This partially explains why projects come in late. However it’s not the whole story. According to Goldratt, there are a few other factors that lead to dissipation of safety. I discuss these next.
Other time wasters
In the previous section we saw that dependencies between activities can eat into safety significantly because delays accumulate while gains don’t. There are a couple of other ways safety is wasted. These are:
Multitasking It is recognised that multitasking – i.e. working on more than one task concurrently – introduces major delays in completing tasks. See these articles by Johanna Rothman and Joel Spolsky, for a discussion of why this is so. I’ve discussed techniques to manage multitasking in an earlier post.
Student syndrome This should be familiar to any one who’s been a student. When saddled with an assignment, the common tendency is to procrastinate until the last moment. This happens on projects as well. “Ah, there’s so much time. I’ll start later…” Until, of course, there isn’t very much time at all.
Parkinson’s Law states that “work expands to fill the allocated time.” This is most often a consequence of there being no incentive to finish a task early. In fact, there’s a strong disincentive from finishing early because the early finisher may be a) accused of overestimating the task or b) rewarded by being allocated more work. Consequently people tend to adjust their pace of work to just make the scheduled delivery date, thereby making the schedule a self-fulfilling prophecy.
Any effective project management system must address and resolve the above issues. The critical chain method does just that. Now with the groundwork in place, we can move on to a discussion of the technique. We’ll do this in two steps. First, we discuss the special case in which there is no resource contention – i.e. multitasking does not occur. The second, more general, case discusses the situation in which there is resource contention.
The critical chain – special case
In this section we look at the case where there’s no resource contention in the project schedule. In this (ideal) situation, where every resource is available when required, each task performer is ready to start work on a specific task just as soon as all its predecessor tasks are complete. Sure, we’ll also need to put in place a process to notify successor task performers about when they need to be ready to start work, but I’ll discuss this notification process a little later in this section. Let’s tackle Parkinson and the procrastinators first.
Preventing the student syndrome and Parkinson’s Law
To cure habitual procrastinators and followers of Parkinson, Goldratt suggests that project task durations estimates be based on a 50% probability of completion. This corresponds to an estimate that is equal to
As discussed earlier, a
- Removal of individual activity completion dates from the schedule altogether. The only important date is the project completion date.
- No penalties for going over the
The above points should be explained clearly to project team members before attempting to elicit
So, how does one get reliable
- Assume that the initial estimates obtained from team members are
- Another option is to ask the estimator how long a task is going to take. They’ll come back to you with a number. This is likely to be their
- Yet another option is to calibrate estimators’ abilities to predict task durations based on their history (i.e. based on how good earlier estimates were). In the absence of prior data one can quantify an estimator’s reliability in making judgements by asking him or her to answer a series of trivia questions, giving an estimated probability of being correct along with each answer. An individual is said to be calibrated if the fraction of questions correctly answered coincides (or is close to) their stated probability estimates. In theory, a calibrated individual’s duration estimate should be pretty good. However, it is questionable as to whether calibration as determined through trivia questions carries over to real-world estimates. See this site for more on evaluating calibration.
- Finally, project managers can use Monte Carlo simulations to estimate task durations. The hard part here is coming up with a probability distribution for the task duration. One commonly used approach is to ask task estimators to come up with best case, worst case and most likely estimates, and then fit these to a probability distribution. There are at least two problems with this approach: a) the only sensible fit to a three point estimate is a triangular distribution, but this isn’t particularly good because it ignores the long tail and b) the estimates still need to be quality assured through independent checks (historical comparison, for example) or via calibration as discussed above – else the distribution is worthless. See this paper for more on the use of Monte Carlo simulations in project management (Note added on 23 Nov 2009: See my post on Monte Carlo simulations of project task durations for a quick introduction to the technique)
Folks who’ve read my articles on cognitive biases in project management (see this post and this one) may be wondering how these fit in to the above argument. According to Goldratt, most people tend to offer their
Getting team members to come up with reliable
The resource buffer
Readers may have noticed a problem arising from the foregoing discussion of
The project buffer
Alright, so now we’ve reduced activity estimates, removed completion dates for individual tasks and ensured that resources are positioned to pick up tasks when they have to. What remains? Well, the most important bit really – the safety! Since tasks now only have a 50% chance of completion within the estimated time, we need to put safety in somewhere. The question is, where should it go? The answer lies in recognising that the bottleneck (or constraint) in a project is the critical path. Any delay in the critical path necessarily implies a delay in the project. Clearly, we need to add the safety somewhere on the critical path. I hope the earlier discussion has convinced you that adding safety to individual tasks is an exercise in futility. Goldratt’s insight was the following: safety should be added to the end of the critical path as a non-activity buffer. He calls this the project buffer. If any particular activity is delayed, the project manager “borrows” time from the project buffer and adds it on to the offending activity. On the other hand, if an activity finishes early the gain is added to the project buffer. Figure 2 depicts a project network diagram with the project buffer added on to the critical path (C1-C2-C3 in the figure).

What size should the buffer be? As a rule of thumb, Goldratt proposed that the buffer should be 50% of the safety that was removed from the tasks. Essentially this makes the critical path 75% as long as it would have been with the original (
The feeding buffer
As shown in Figure 2 the project buffer protects the critical path. However, delays can occur in non-critical paths as well (A1-A2 and B1-B2 in the figure). If long enough, these delays can affect subsequent critical path. To prevent this from happening, Goldratt suggests adding buffers at points where non-critical paths join the critical path. He terms these feeding buffers.

Figure 3 depicts the same project network diagram as before with feeding buffers added in. Feeding buffers are sized the same way as project buffers are – i.e. based on a fraction of the safety removed from the activities on the relevant (non-critical) path.
The critical chain – a first definition
This completes the discussion of the case where there’s no resource contention. In this special case, the critical chain of the project is identical to the critical path. The activity durations for all tasks are based on t50 estimates, with the project buffer protecting the project from delays. In addition, the feeding buffers protect critical chain activities from delays in non-critical chain activities.
The critical chain – general case
Now for the more general case where there is contention for resources. Resource contention implies that task performers are scheduled to work on multiple tasks simultaneously, at one or more points along the project timeline. Although it is well recognised that multitasking is to be avoided, most algorithms for finding the critical path do not take resource contention into account. The first step, therefore, is to resource level the schedule – i.e ensure that tasks that are to be performed the same resource(s) are scheduled sequentially rather than simultaneously. Typically this changes the critical path from what it would otherwise be. This resource leveled critical path is the critical chain.
The above can be illustrated by modifying the example network shown in Figure 3. Assume tasks C1, B2 and A2 (marked X) are performed by the same resources. The resource leveled critical path thus changes from that shown in Figures 2 and 3 to that shown in Figure 4 (in red). As per the definition above, this is the critical chain. Notice that the feeding buffers change location, as (by definition) these have to be moved to points where non-critical paths merge with the critical path. The location of the project buffer remains unchanged.

Endnote
This completes my introduction to the critical chain method. Before closing, I should mention that there has been some academic controversy regarding the critical chain method. In practice, though, the method seems to work well as evidenced by the number of companies offering consulting and software related to critical chain project scheduling.
I can do no better than to end with a list of online references which I’ve found immensely useful in learning about the method. Here they are, in no particular order:
Critical Chain Scheduling and Buffer Management . . . Getting Out From Between Parkinson’s Rock and Murphy’s Hard Place by Francis Patrick.
Critical Chain: a hands-on project application by Ernst Meijer.
The best place to start, however, is where it all began: Goldratt’s novel, Critical Chain.
(Note: This essay is a revised version of my article on the critical chain, first published in 2007)



Great Blog, just stumbled upon it and just kept reading. Altough knowing the goal, i never realised that i could be so simple.
thanxs very much!
LikeLike
Martijn Logtenberg
September 3, 2009 at 2:33 am
Martijn,
Thanks for the kind words!
Regards,
Kailash.
LikeLike
K
September 3, 2009 at 6:43 am
This article has really englightened me about the rudiments of critical chain method, recommended for the basic beginner.
Thanks
LikeLike
Loye
March 17, 2010 at 11:33 pm
Loye,
I’m glad you found it helpful. Many thanks for the feedback.
Regards,
Kailash.
LikeLike
K
March 19, 2010 at 6:00 am
A very coherent approach!
Thanks for the insights! 😉
LikeLike
Marius
May 30, 2010 at 10:48 pm
well written .
LikeLike
Ritesh
March 6, 2011 at 10:19 pm
This article on critical chain is really good and eye opener even for experienced scheduler.
LikeLike
Hari
April 17, 2011 at 8:41 pm
Hari,
Thanks! I’m glad you found it useful.
Regards,
K.
LikeLike
K
April 17, 2011 at 8:45 pm
The critical chain method is often a confusing topic but you did a great job explaining it. Thank you for sharing.
LikeLike
Sid
November 4, 2011 at 5:20 am
Hi Sid,
Thank you for the feedback!
Regards,
Kailash.
LikeLike
K
November 4, 2011 at 5:42 am
Is it convenient to explain the CCM by Gantt Chart? If so, I would request (i) normal resource loading and leveling and (ii) converting the same resource loading and leveling under critical Chain Method.
LikeLike
hafeez Malik
January 24, 2012 at 3:05 am
I’m learning this method these days, read several articles. Yours is the best I think. thanks.
LikeLike
Catherine
January 6, 2016 at 1:08 pm
Thanks for reading and taking the time to comment!
LikeLike
K
January 7, 2016 at 7:02 pm